Choose timezone
Your profile timezone:
The 25th annual conference of the European Network for Business and Industrial Statistics (ENBIS) will be hosted by the University of Piraeus and will take place at the central building in the city center of Piraeus (Greece), from September 14 to 18. The conference sessions are scheduled from 15th to 17th September, with the administrative meetings, the pre- and post-conference courses and workshops taking place on the 14th and 18th September.

The annual conference features invited and contributed sessions, workshops and panel discussions, pre- and post-conference courses, as well as talks from distinguished keynote speakers and award winners.
This year's keynote speakers include Jennifer van Mullekom (Virginia Tech, USA) and George Moustakides (University of Patras, Greece).
We are also pleased to announce that Alberto Ferrer (Universidad Politécnica de Valencia, Spain) will receive the ENBIS Box Medal in recognition for his remarkable contributions to the development and the application of statistical methods in European business and industry.
We cordially invite you not only to engage in highly rewarding scientific and professional exchange during the conference, but also to find some leisure time and explore the city of Piraeus, Athens and Greece.
Warmly welcome,
The ENBIS-25 Organizing Committee
https://conferences.enbis.org/event/73/
The on-line detection of a change in the statistical behavior of an observed random process is a problem that finds numerous applications in diverse scientific fields. The "Sequential Detection of Changes" literature addresses theoretically and methodologically the specific problem offering a rich collection of theoretical results and a multitude of methods capable of efficiently responding to different types of changes. The majority of the proposed detection strategies enjoy some form of (asymptotic) optimality according to well defined criteria. Unfortunately, these performance measures are notoriously complicated and have been the subject of long and intense discussions within the community as to which is more appropriate to adopt. In this talk by following a bottom/up logic we attempt to build proper performance criteria by first understanding and categorizing the mechanisms that can generate changes. Interestingly, through our analysis we rediscover the same criteria that were arbitrarily proposed in the literature only now we are at a position to identify the category of changes where each criterion is most suitable for. For each criterion we recall the corresponding optimal detection structure and we also discuss possible variations.
The increased use of random forest (RF) methods as a supervised statistical learning technique is primarily attributed to their simplicity and ability to handle complex datasets. A RF consists of multiple decision trees, which can be categorized into two types based on how they process node splitting: parallel and oblique. Axes-parallel decision trees split the feature space using a single feature at a time, aligning the hyperplane with the coordinate axes. In contrast, oblique decision trees partition the space with hyperplanes that are oblique to the axes, often leading to higher predictive power. This work introduces a novel method to create an oblique RF for regression tasks. The base learner in this ensemble is an oblique decision tree where the splitting hyperplane is obtained through a weighted support vector machine classifier. As in standard RF, a bootstrap sample is drawn before growing each tree, and a random subset of predictors is considered at each node. The algorithm splits the data at each node by applying the classifier to the most correlated features, selected from the current subset, with the dependent variable. The cardinality of the selected subset is chosen randomly to increase diversity among the base learners. The proposed oblique RF is then evaluated on real-world benchmark datasets and compared to other state-of-the-art machine learning techniques. Results show a consistent improvement in predictive performance.
In this study, we investigate the economic impact of COVID-19 on employment within Italian firms. In particular, we analyse how employment levels were affected across different types of firms and assess the extent of the impact. We also examine the role of public subsidies provided during the COVID-19 period and evaluate the occupational mix between ‘flexible’ and ‘non-flexible’ employees. Specifically, to analyse changes in employment, we employ a transition probability matrix (TPM) to identify firms experiencing varying rates of employment growth or decline. We explore key firm characteristics—such as export activity, productivity, profitability, and size—to explain patterns of heterogeneity and their persistence over time. The model is expanded to incorporate government subsidies and labour market variables, providing a deeper understanding of the interaction between firm attributes and employment dynamics. By comparing the pre-pandemic and pandemic periods, we assess the specific impact of COVID-19 on employment trends. The results confirm that the effects on employment vary by firm type, with particularly pronounced impacts observed in the Horeca sector.
This study focuses on bankruptcy prediction for micro-sized enterprises, a segment often overlooked in credit risk modeling due to the limited reliability of their financial data. Building on prior research that highlights the importance of sector-specific strategies, we construct separate predictive models for selected industries using a dataset of 84,019 Italian micro-enterprises, of which only 1,308 (1.15%) experienced default. The low default rate presents a challenging classification task, especially when analyzed at the industry level. To address the limitations of models relying solely on balance sheet data, we introduce an innovative source of non-financial information: features derived from the HTML structure of company websites. These web-based variables are integrated with traditional financial indicators to improve predictive performance. A cross-validation framework is employed to ensure the robustness and generalizability of our models. Results reveal that website features provide substantial predictive value, particularly in sectors where a strong digital presence is maintained. The importance of these features varies across industries, highlighting sector-specific differences not only in financial behavior but also in web-related activity. Our findings suggest that website-derived data offer a novel and valuable signal for early-warning systems, particularly in contexts with limited financial information. This approach contributes to the development of more accurate and industry-sensitive credit risk models for micro-enterprises.
New data acquisition technologies allow one to gather amounts of data that are best represented as functional data. In this setting, profile monitoring assesses the stability over time of both univariate and multivariate functional quality characteristics. The detection power of profile monitoring methods could heavily depend on parameter selection criteria, which usually do not take into account any information from the out-of-control (OC) state. This work proposes a new framework, referred to as adaptive multivariate functional control chart (AMFCC), capable of adapting the monitoring of a multivariate functional quality characteristic to the unknown OC distribution by combining p-values of partial tests corresponding to Hotelling $T^2$-type statistics calculated at different parameter combinations. Through an extensive Monte Carlo simulation study, the performance of AMFCC is compared with methods that have already appeared in the literature. Finally, a case study is presented in which the proposed framework is used to monitor a resistance spot welding process in the automotive industry. AMFCC is implemented in the R package funcharts, available on CRAN.
In statistical process monitoring, control charts typically depend on a set of tuning parameters besides its control limit(s). Proper selection of these tuning parameters is crucial to their performance. In a specific application, a control chart is often designed for detecting a target process distributional shift. In such cases, the tuning parameters should be chosen such that some characteristic of the out-of-control run length of the chart, such as its average, is minimized for detecting the target shift, while the control limit is set to maintain a desired in-control performance. However, explicit solutions for such a design are unavailable for most control charts, and thus numerical optimization methods are needed. In such cases, Monte Carlo-based methods are often a viable alternative for finding suitable design constants. The computational cost associated with such scenarios is often substantial, and thus computational efficiency is a key requirement. To address this problem, a two-step design based on stochastic approximations is presented, which is shown to be much more computationally efficient than some representative existing methods. A detailed discussion about the new algorithm's implementation along with some examples are provided to demonstrate the broad applicability of the proposed methodology for the optimal design of univariate and multivariate control charts.
JMP Pro 19 and JMP Student Edition 19, coming in October 2025, is a major advancement of JMP’s statistical modeling capabilities. In this presentation we highlight three of its most important and impactful new developments. The new Bayesian Optimization platform which combines model optimization via the Profiler with Gaussian Process (GaSP) based active learning methods. Essentially any industrial multiple response optimization supported by the Profiler can be solved using less time and fewer resources with this new capability. It simplifies industrial formulation projects because GaSP models are more robust to complicated linear constraints than linear statistical models. Another new capability is the Fit Mixed platform has a built-in Stability Analysis / expiration date calculator that uses random coefficient models to directly derive the distribution of the expiration date, yielding a more rigorous approach than the existing ICH Guidelines based approach. Finally, we will demonstrate the new Peak Modeling and Baseline Correction capabilities of the Functional Data Explorer, which makes more efficient use of chromatographic data in analytical chemistry by making it possible to deconvolve poorly resolved peaks.
Mixture experiments are commonplace in the chemical industry, where some or all the factors are components of a mixture expressed as percentages. These components are subject to a linear equality constraint, which forces the sum of the proportions to equal one. In most cases, the components are box-constrained, meaning there are constraints on the minimum and maximum concentrations of each component. Finally, multicomponent linear constraints involving several factors may also be present. All these constraints define a polytope in certain dimension (bounded convex polyhedron). At Effex, we have implemented a robust optimal design algorithm that uses point exchange for constrained factors, combined with an efficient enumeration of the polytope vertices, and coordinate exchange for other factors (e.g. factors associated with process parameters). The Effex algorithm has the advantage of finding optimal designs for problems involving a large number of components and complex scenarios such as mixture of mixtures problems, hard-to-change factors and blocking.
Over the past decade, ongoing collaboration in research and technology transfer between faculty and professionals from Ecuadorian Escuela Politécnica Nacional and Universidad Nacional de Chimborazo, and Spanish Universidade da Coruña, has led to multiple developments in computational statistics aimed at solving real-world problems in industry and engineering.
Specifically, our work has focused on the development of R packages covering a wide range of applications in statistical quality control and reliability analysis. The qcr package, for instance, was created to provide practical tools for statistical process control using control charts—univariate, multivariate, and functional—as well as process capability analysis. Moreover, in the field of design of experiments, we developed the ILS package, which offers tools for interlaboratory studies involving complex data, and the r6qualitytools package, aimed at supporting broader quality improvement applications. On the reliability side, we created the FCGR and TTS packages. These implement nonparametric methods developed by the authors to estimate lifetime distributions of materials under fatigue, and to predict master curves and service lifetimes for viscoelastic materials.
All of these packages are open-access and designed to equip practitioners with user-friendly computational tools for monitoring, analyzing, and improving processes in industrial and service contexts—especially when working with complex or nonstandard data, or when estimating material lifetimes under stress.
In a client project focused on asset registration, we transitioned from a publicly available LLM (Gemini) to a locally hosted LLM to prevent the potential leakage of sensitive manufacturing and customer data. Due to hardware constraints (GPUs with a maximum of 12 GB VRAM), the performance of local LLMs was initially inferior to hosted models. Therefore, prompt optimization became crucial to achieve comparable output quality.
We explored the application of LLM-specific statistical evaluation metrics — G-Eval, Answer Relevance, Prompt Alignment, Sensitivity, and Consistency — using the Langfuse framework deployed on-premises. We evaluated three quantized models (llama3.1 8b, mistral 7b , deepseek-llm 7b) on a dataset of 200 simulated asset registration requests in multiple languages (German, English, Turkish), reflecting real-world operational complexity.
Reference values for evaluation were manually extracted by human coders. Prompt engineering techniques, including Zero-shot, One-shot, and Few-shot strategies, were applied systematically. Only information present in the registration prompts was extracted; no hallucinations occurred (temperature was fixed at 0). However, significant effort was needed to maximize information extraction through tailored prompts.
This case study demonstrates how statistical metrics can guide and validate prompt optimization, especially under constrained computing conditions and multilingual input. We invite discussion on alternative metrics, further application domains, and lessons learned from fitting models primarily trained for English to German and mixed-language tasks.
Explainable AI (XAI) approaches, most notably Shapley values, have become increasingly popular because they reveal how individual features contribute to a model’s predictions. At the same time, global sensitivity analysis (GSA) techniques, especially Sobol indices, have long been used to quantify how uncertainty in each input (and combinations of inputs) propagates to uncertainty in the model’s output. Prior work (e.g., Owen 2014) highlighted the theoretical connections between Shapley‐based explanations and Sobol‐based sensitivity measures.
FANOVA (functional ANOVA) graphs were created to visualize main‐effect Sobol indices and total interaction terms in a straightforward graphic form, making it easy to see which inputs (and pairs of inputs) drive model behavior. In this work, we apply the same general concept to Shapley values and the recently introduced Shapley interaction indices. By translating complex machine‐learning models into analogous "Shapley graphs", we provide equally intuitive visual representations of both individual feature contributions and feature interactions. Through several real‐world case studies, we show that these Shapley‐based graphs are just as clear and user‐friendly as FANOVA graphs, and we discuss how the two methods compare in terms of interpretability.
References
Owen, A. B. (2014). Sobol’ indices and Shapley value. SIAM/ASA Journal on Uncertainty Quantification, 2, 245–251.
Fruth, J.,Roustant, O. & Kuhnt, S. (2014). Sensitivity Analysis and FANOVA Graphs for Computer Experiments. Journal of Statistical Planning and Inference, 147, 212–223
Muschalik, M., Baniecki, H., Fumagalli, F., Kolpaczki, P., Hammer, B., & Hüllermeier, E. (2024). SHAP-IQ: Shapley Interactions for Machine Learning. In Proceedings of the Thirty-Eighth Conference on Neural Information Processing Systems Datasets and Benchmarks Track
Large language models (LLMs) are increasingly capable of simulating human-like personalities through prompt engineering, presenting novel opportunities and challenges for personality-aware AI applications. However, the consistency and stability of these simulated personalities over time and across contexts remain largely unexplored. In this study, we propose an integrated framework to systematically evaluate LLM personality consistency using psychometric tools combined with machine learning-based textual analysis. We generate diverse text corpora by prompting LLMs with varied personality-specific instructions and social contexts, ensuring a broad range of stylistic and psychological traits in the generated data. We then employ a Dual Enhanced Network (DEN) architecture to extract both long-term and short-term personality representations from the generated texts. Our framework quantifies personality drift and robustness using statistical measures and machine learning-based evaluation across multi-session outputs. Experimental results reveal that LLM personalities fluctuate significantly depending on prompt design and conversational context. We further discuss implications for model alignment, control strategies, and the deployment of personality-driven AI systems. This work provides a novel methodology for evaluating personality emulation in LLMs and highlights important considerations for ethical and robust personality-aware applications.
In this work we consider one-sided EWMA and CUSUM charts with one Shewhart-type control limit, and study their performance in the detection of shifts, of different magnitude, in the parameters of a two-parameter exponential distribution. Using Monte Carlo simulation, we calculate the run length distribution of the considered charts and evaluate their performance, focusing on the average run length and the expected average run length. Furthermore, we provide empirical rules for their statistical design. The preliminary results show that the considered combined schemes have better performance than the usual EWMA and CUSUM charts, especially in the detection of decreasing shifts in process parameters. An illustrative example, based on real data, is also discussed.
Acknowledgement: This work has been partly supported by the University of Piraeus Research Center.
A single Shewhart chart based on a Max-type statistic has been suggested for monitoring a process using one control charts, based on a single plotting statistic, and detecting changes in its parameters. To improve its power, it is suggested to apply one or more supplementary rules based on run statistics, known as runs rules. Supplementary runs rules have been used since the 1950s to improve the performance of control charts in detecting small to moderate shifts in process parameters. Recently, there has been an increased interested in proposing improved control charts for monitoring a shifted exponential process, i.e. a process where the critical-to-quality characteristic follows a shifted exponential distribution. However, the case of single control charts with runs rules has not been investigated so far. In this work, we introduce and study a Max-type control chart supplemented with runs rules for detecting changes in the parameters of a shifted exponential process. Using a Markov chain method, we calculate the run length distribution of the proposed charts whereas we assess their performance, in terms of the average run length and the expected average run length metrics. In addition, the performance of the proposed charts is compared with other competitive single control charts, such as the SEMLE-Max chart and the RS-SEMLE-Max chart. Finally, a real dataset is used to illustrate the implementation of the proposed charts in practice.
Monitoring time between events, operational delays or responding to a customer call is essential for maintaining and thriving to enhance service quality. Several aspects of the processes, including location such as median time, variability and shape, are pivotal. This paper introduces a Phase-II distribution-free cumulative sum (CUSUM) procedure based on a combination of three orthogonal rank statistics for simultaneously monitoring location, scale, and skewness aspects. The idea of multi-aspect process monitoring involving three orthogonal aspects using a single combined statistic is new, and previous works on Phase-II monitoring used three non-orthogonal statistics. The orthogonal statistics have certain advantages in performance and interpretation. A quadratic combination of three component statistics based on the Legendre polynomial is proposed for monitoring the shift in location, scale, and skewness. Earlier Legendre polynomial-based rank statistics were used in Phase-I applications but never studied in the context of Phase-II applications. Implementation design and post-signal follow-up procedure for identifying which parameter is more responsible for the signal are discussed. The In-control robustness of the proposed scheme is studied via simulation. The run-length properties of the proposed scheme are compared with various CUSUM schemes. The proposed scheme displays outstanding out-of-control performance in identifying a broad class of shifts involving one or more of the three parameters in an underlying process distribution. An illustration of the proposed scheme for monitoring the time it takes to deliver food items by an e-commerce facility is presented to explain manufacturing quality monitoring applications. We finally offer some concluding remarks.
Passenger discomfort during flight is greatly influenced by seat interface pressure whose effect varies with time of exposure and passenger anthropometric characteristics.
Existing studies have largely explored static relationships between anthropometric features, seat-interface pressure, and discomfort perception without leveraging these findings for building predictive systems for passenger discomfort and failing to account for the temporal dynamics of pressure exposure.
To address this limitation, our study proposes a predictive framework for discomfort based on Time Series Classification (TSC) algorithms and fusion strategies to combine temporal pressure data with static passenger anthropometric features (gender, age, height, weight, BMI).
Ten multivariate TSC algorithms have been evaluated under three different strategies for fusing anthropometric data with time series inputs: (1) embedding static features as additional artificial timesteps; (2) extracting statistical features from the temporal data, so that the extracted features can be directly combined with static features at the final transformation stage; (3) replicating static features across all timesteps (i.e., repeated static approach), allowing them to be treated as parallel channels during sequence processing.
The performance of the predictive strategies under comparison has been evaluated using a real dataset containing seat pressure time series and subjective discomfort ratings collected during 123 laboratory test sessions. Experimental results highlight the relevance of integrating passenger anthropometric features to temporal seat pressure for enhancing seat discomfort prediction. The repeated static approach leads to significant improvements in predictive performance across all TSC algorithms increasing accuracy up to 32%.
Acknowledgements
This study was carried out within the MICS (Made in Italy– Circular and Sustainable) Extended Partnership and received funding from the European Union Next-Generation EU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR) – MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.3 –D.D. 1551.11-10-2022, PE00000004). This manuscript reflects only the authors’ views and opinions, neither the European Union nor the European Commission can be considered responsible for them.
Modern, flexible, data-driven pricing techniques are required for revenue management in the car rental sector, in order to better meet the ever-changing market conditions and erratic customer demand. Traditional pricing approaches often fall short in capturing the inherent volatility and complexity that exist in the particular industry. However, the growing availability of real-time data has created new opportunities for car rental companies to adopt dynamic pricing models powered by data analytics. The incorporation of Artificial Intelligence into pricing strategies is capable of reshaping the landscape of revenue optimization.
This study explores the use of machine learning-based dynamic pricing within the car rental domain. It presents a comprehensive framework centered on the implementation of Machine and Deep Learning methods, tailored to this sector’s unique characteristics. Key variables—such as competitor pricing and fleet availability—identified as critical by domain experts, are integrated into predictive models that forecast demand and generate pricing recommendations across various vehicle categories and rental locations.
Tourism stakeholders increasingly seek data-driven methods for tailoring travel experiences to individual interests. This study investigates whether the preferences that travelers express implicitly on social media, together with operational travel data, can be transformed into high-fidelity digital profiles and, subsequently, into personalized travel packages.
During the first phase, we will assemble and analyze a rich, multi-source dataset encompassing airline schedules, historical fare dynamics, point-of-interest (POI) metadata—including categories such as buildings, museums and squares—and user-generated content (e.g. social-media posts, geotagged check-ins, reviews). Statistical analysis forms the critical foundation: exploratory techniques (descriptive statistics, visualization) and inferential methods (correlation analysis, factor analysis, time-series decomposition) will uncover baseline patterns such as seasonal price fluctuations, route-popularity trends, POI co-visitation clusters (e.g. correlations between museum visits and nearby square activity) and other factors influencing user choices.
In subsequent phases, machine-learning techniques—particularly clustering algorithms—will synthesize the analyzed data to extract latent user preferences and construct probabilistic preference profiles.
By integrating robust statistical analysis of diverse tourism data with machine learning and heuristic optimization, the study aims to advance intelligent tourism systems and create travel experiences that are more relevant, cost-effective and user-centric.
This research proposes a novel framework for automating the generation of AI personas using Agentic AI systems, designed to be MCP-compliant for robust interoperability and seamless tool integration. Traditionally, creating AI personas involves repetitive prompt engineering, manual calibration, and continuous human intervention, which can be time-consuming and error-prone. In contrast, we leverage the Agentic AI paradigm, where agents can perceive, plan, and act autonomously, to enable LLM-driven agents to construct, simulate, and refine dynamic personas aligned with psychological models such as the Big Five. Within MCP-compliant environments, these agents can retrieve domain-relevant data, invoke specialized APIs and modules, and iteratively adapt their behaviors based on interaction feedback, reducing the need for extensive manual oversight. By maintaining coherent memory and context-sharing across agents, this approach bridges the gap between static character modeling and adaptive user simulation, supporting diverse applications from A/B testing in marketing to social system modeling. Our findings highlight how Agentic AI can serve not only as powerful reasoning engines but also as self-sufficient persona architects capable of evolving with changing user or system contexts for more robust, data-driven, and adaptive interactive systems.
Deep learning (DL) models are significantly impacted by label and measurement noise, which can degrade performance. Label noise refers to wrong labels (Y) attached to samples, whereas measurement noise refers to the samples (X) that are corrupted due to issues during their acquisition. We present a generic approach for efficient learning in the presence of such noise, without relying on ground truth labels. Our approach is inspired by the work of Raymaekers et al. (2021) who introduced so-called “classmaps” for vizualizing classification results. The approach we introduce employs a weakly supervised learning paradigm, training a DL classifier on noisy datasets and using the predicted class for splitting the noisy dataset. A Variational Autoencoder (VAEs) is then used on each of the subsets of the data to create latent representations. By calculating the degree of outlyingness of each sample in the corresponding latent space, class-specific maps are generated that visually represent the different noise sources. This is particularly interesting because measurement noise can be disregarded, as it denotes poor-quality samples. In contrast, label noise can be presented to a labeller for verification, since those samples have a high probability of being mislabelled.
We will apply the approach using two different datasets. We will use the Fashion MNIST dataset for explaining the different steps of the framework, and a practical dataset of classifying insects on sticky plates to demonstrate the versatility and effectiveness of it.
This work presents a methodology for condition monitoring of spur gearboxes based on AI-enhanced multivariate statistical process control. Gearboxes are critical components in rotating machinery, and early fault detection is essential to minimize downtime and optimize maintenance strategies. Vibration signals are a non-invasive means to assess gearbox conditions under varying load and rotational speed conditions.
Condition indicators (CIs) are extracted from the time, frequency, and time-frequency domains to capture relevant features of the vibration signals. These indicators are fused into a multivariate data matrix and analyzed using Principal Component Analysis (PCA). Control limits are established using Hotelling’s $T_A^2$ and Squared Prediction Error (SPE) statistics to identify deviations from healthy behaviour.
To enhance diagnostic capabilities, simulated faults with different degrees of severity are introduced and classified using a Random Forest model. This hybrid approach enables early fault detection and severity assessment by combining multivariate control charts with machine learning-based classification.
All signal processing, statistical analysis, and machine learning modelling were performed in R software, an open-source environment suited for multivariate and predictive analytics.
The results demonstrate that the proposed methodology effectively detects incipient faults and distinguishes between different fault levels, providing a valuable tool for smart maintenance in industrial applications.
The exponentially weighted moving average (EWMA) control chart was proposed already in 1959 and it became one of the most popular devices in statistical process monitoring (SPM) in the last decade of the previous century. Besides its most popular version for monitoring the mean of a normal distribution, many other statistical parameters were deployed as target for setting up an EWMA chart. Here, we consider its application for monitoring the correlation coefficient (cc), which was rarely investigated so far. The distribution of the sample cc, known as Pearson (Bravais) cc, has been known since Fisher (1921). However, this distribution is quite complex if the underlying correlation is different to zero. Here, we discuss the calculation of the zero-state average run length (ARL) for various sample sizes. It turns out that depending on the sample size, one uses either well-known procedures like the Gauß-Legendre Nyström procedure for large samples sizes, whereas for smaller ones (< 20), one has to stick to collocation. Moreover, we examine further configuration details and provide some guidelines. An application for monitoring sensor health completes this contribution.
Modern industrial systems generate high-dimensional data streams often used for statistical process monitoring (SPM), i.e., distinguishing between multiple in-control and out-of-control (OC) states. While supervised SPM methods benefit from labeled data in assessing the process state, label acquisition is often expensive and infeasible at large scale. This work proposes a novel stream-based active learning framework for SPM that optimally selects data points to label under a constrained budget. Unlike traditional active learning methods, which assume independent data, our approach explicitly models temporal dependencies by integrating partially hidden Markov models to combine labeled and unlabeled information. The proposed method addresses both class imbalance and the emergence of previously unseen OC states. A dual criterion is developed to balance exploration (i.e., discovering new OC conditions) and exploitation (i.e., improving classification accuracy on known states). The labeling strategy operates in real-time, providing decisions for each incoming data point. Through a simulation study and a case study on resistance spot welding in the automotive industry, the proposed method is demonstrated to improve SPM performance, especially when labeling resources are scarce.
Acknowledgements: The research activity of C. Capezza and A. Lepore was supported by Piano Nazionale di Ripresa e Resilienza (PNRR) - Missione 5 Componente 2, Investimento 1.3-D.D. 1551.11-10-2022, PE00000004 within the Extended Partnership MICS (Made in Italy - Circular and Sustainable). This manuscript reflects only the authors' views and opinions, neither the European Union nor the European Commission can be considered responsible for them.
Nowadays, big data is generated real-time in the majority of industrial production processes. Happenstance data is characterized by high volume, variety, velocity and veracity (4v of big data).
In this study production data from industrial purification process is analyzed to assess process performance and its relations with product quality. For this purpose, a comprehensive data preprocessing strategy is developed first. It comprises of data driven methods such as parametric time warping for time profile synchronization, definition of process steps, outlier detection and missing values removal. Importantly, also expert-driven steps are applied to extract more than 200 relevant features for different process variables and different process steps.
Finally, different combinations of preprocessed process data from multiple runs, which are contributing to single batch quality data, are analyzed with univariate and multivariate statistical tools. This allows to explore and visualize relationships between process and product in efficient manner to ease process understanding and monitoring.
This study presents a statistical framework developed within the TouKBaSEED (Tourism Knowledge Base for Socio-Economic and Environmental Data Analysis) research project to support sustainable tourism planning in the port city of Piraeus, Greece. It integrates quantitative and qualitative methods, combining survey data from returning tourists, new arrivals, and residents with sentiment analysis of over 25,000 user reviews from platforms such as Google Maps, TripAdvisor, and Booking.com. The analyses include descriptive statistics, factor analysis, and regression modeling to examine visitor satisfaction, sustainability perceptions, and resident attitudes toward tourism development. In parallel, social media reviews were analyzed to explore traveler sentiment, seasonal patterns, and concerns regarding infrastructure. Findings reveal a complex interplay between tourism impacts and sustainability. Visitor satisfaction is most influenced by perceptions of
environmental quality, followed by social and economic sustainability. Tourists who viewed Piraeus as environmentally responsible reported higher levels of satisfaction. Similarly, residents who perceived tourism as supporting the environment and social cohesion were more likely to view its economic effects positively. Social media reviews reinforced these findings, frequently highlighting gastronomy, culture, and accessibility as strengths, while noting recurring issues with cleanliness, pricing, and congestion. Overall, the study demonstrates the value of integrating traditional statistical methods with digital analytics to capture the full spectrum of tourism impacts. This approach provides a comprehensive understanding of how sustainability perceptions influence visitor and resident attitudes, offering a data-informed foundation for inclusive and resilient tourism strategies in urban destinations.
This study presents analytical findings from the GreCO (Green Cultural Oases) project, funded under the European Urban Initiative (EUI). GreCO promotes sustainable cultural tourism in urban environments by leveraging digital innovation, local stakeholder collaboration, and intercultural engagement. Within this framework, a multilingual survey was conducted with over 350 respondents to examine tourist motivations, preferences, and perceptions in urban settings, with a particular focus on the Athens Riviera, a coastal zone in the southern suburbs of Athens undergoing strategic sustainable development. The dataset encompasses a wide range of travel-related dimensions, including travel frequency and purpose, types of accommodation, preferred activities, emotional responses, and post-visit behavioural intentions. Descriptive and inferential statistical methods are applied to identify patterns and correlations between socio-demographic variables (e.g., age, nationality, education) and key experiential indicators such as psychological comfort, place attachment, and perceived authenticity. Particular emphasis is placed on the role of digital platforms, review sites, and social media in shaping destination image and influencing travel decisions. Initial results yield actionable insights into visitor expectations and satisfaction, revealing distinct tourist profiles that can inform more inclusive, experience-driven tourism strategies. These findings also support the development of user-centred digital applications and smart tourism services envisioned within the GreCO project. The study contributes to the growing field of statistics in tourism, offering an evidence-based approach to sustainable destination management and underscoring the value of integrating data-driven analysis with participatory planning in urban tourism.
Cellwise outliers, introduced by Alqallaf et al. (2009), represent a shift from the traditional rowwise approach in robust statistics by focusing on individual anomalous data cells rather than entire observations. This paradigm offers significant advantages, such as pinpointing which variables cause outlying behavior and preserving more usable data, particularly in high-dimensional settings where discarding full rows can lead to substantial information loss. However, the cellwise approach introduces new challenges, including complications from data transformations, difficulty in detecting non-marginal outliers due to hidden dependencies, and the exponential growth of possible outlier patterns with dimensionality. These issues complicate tasks like covariance estimation, regression, and PCA, demanding new statistical methods. While promising methods like the cellwise MCD estimator have emerged, many existing approaches lack strong theoretical foundations and are often tested in limited scenarios. Continued innovation is essential to fully address the complexities of cellwise contamination and to build robust tools that perform reliably in diverse, real-world data scenarios.
I will tell the story of a social media influencing mission to empower every scientist and engineer in the world with the tools of Statistical Design and Analysis of Experiments. I'll share compelling examples, talk about why I started this, and how I did it. Using visual explorations of impressions data you will see what we can learn about using online channels to promote the value of statistics.
In the digital era, artificial intelligence (AI) is transforming how industries operate—powering breakthroughs in image analytics, large language models (LLMs), deep learning, reinforcement learning, hybrid modeling, and real-time decision-making.
This talk will reframe the narrative around AI, not as a hype or threat, but as an opportunity for the statistics community to lead with purpose and clarity. Statistical thinking is the backbone of Trustworthy and Responsible AI principles, core statistical concepts are critical such as:
Garbage In, Garbage Out (GIGO): emphasizes that data need to be of sufficient quality and trusted for model building
Outlier detection and extrapolation awareness: Preventing misleading conclusions and confirmation bias.
Model complexity and generalization: Balancing bias and variance to avoid overfitting or underfitting.
Uncertainty quantification: Making informed decisions under uncertainty
As AI continues to evolve, the statistics community must embrace a growth mindset. This talk will offer practical strategies:
Engage proactively with domain experts and AI practitioners.
Communicate the value of statistical rigor in business and engineering contexts.
Teach others how to define “good enough” in decision-making, grounded in uncertainty and risk.
Statistics is the language of data and the foundation of Industrial AI. The future of AI needs statisticians as leaders, let’s shape the future together.
Many business process and engineering design scenarios are driven by an underlying inverse problem. Rather than iteratively exercise a computationally expensive system model to find a suitable design (i.e., match a target performance vector), one might instead design an experiment and conduct off-line system model simulations to fit an inverse approximation, then use the approximation to instantaneously indicate designs meeting multivariate performance targets. This talk examines issues in defining optimal designs for fitting such inverse approximations.
Bayesian Optimization has emerged as a useful addition to the DOE toolbox, well-suited for industrial R&D where resource constraints incentivize spending a minimal number of experiments on complex optimization problems.
While Bayesian Optimization is quite simple to use in principle, the experimenter still has to make choices regarding their strategy and algorithm setup. The question is, how sensitive is optimization performance to these choices?
This presentation looks at how these strategic choices affect optimization speed and reliability across benchmarks that mimic physical processes. These simulations were used to investigate choices like initial data set sizing, acquisition function selection, replication strategy and termination criterion. The results demonstrate that initial data set size mainly affects consistency of outcomes across different problems, rather than average run time. The findings provide practical guidance for users seeking to use Bayesian Optimization effectively in industrial settings.
Model-based approaches are commonly used in the analysis, control and optimization of biosystems. These models rely on knowledge of physical, chemical and biological laws, such as conservation laws, transport phenomena and reaction kinetics, which are usually described by a system of non-linear differential equations.
Often our knowledge of the laws acting on the system is incomplete. These gaps in our knowledge are also referred to as missing physics. Experimental data can be used to fill in such missing physics.
Universal Differential Equations (UDE) have recently been proposed to learn the missing parts of the structure. These UDE use neural networks to represent terms of the model for which the underlying structure is unknown.
Because the opaque nature of neural networks is often not desirable in a scientific computing setting, UDE based techniques are often combined with interpretable machine learning techniques, such as symbolic regression. These techniques post-process the neural network to a human-readable model structure.
Because neural networks are data-hungry, it is important that these applications gather highly informative data. However, current model based design of experiment (MbDoE) methodology focuses on parameter precision or discriminating between a finite number of possible model structures. When part of the model structure is entirely unknown, neither of these techniques can be directly applied.
In this presentation, we propose an efficient data gathering technique for filling in missing physics with a universal differential equation, made interpretable with symbolic regression.
More specifically, a sequential experimental design technique is developed, where an experiment is performed to discriminate between the plausible model structures suggested by symbolic regression. The new data is then used to retrain the UDE, which leads to a new set of plausible model structures by applying symbolic regression again.
This methodology is applied to a bioreactor, and is shown to perform better than a randomly controlled experiment, as showcased here:
https://docs.sciml.ai/Overview/dev/showcase/optimal_data_gathering_for_missing_physics/
Project monitoring practices have significantly evolved over the past decades. Initially grounded in traditional methodologies such as Earned Value Management (EVM), these practices have advanced to incorporate control charts and sophisticated techniques utilizing Artificial Intelligence (AI) and Machine Learning (ML) algorithms to predict final project costs and durations. Despite these considerable multidisciplinary advancements, one fundamental question remains unanswered: When should a project be monitored? Our proposal aims to integrate several established techniques to define optimal review periods based on predefined criteria, thereby assessing whether the project will be delivered on time. Specifically, we combined the Earned Duration Management (EDM) methodology with Monte Carlo simulation to generate a comprehensive dataset. Machine Learning models, enhanced by the Boruta feature selection technique, were then applied to identify eight key review periods capable of predicting project delays, with minimal performance loss. The models demonstrated robust performance, with area under the receiver operating characteristic curve (AUROC) values of 0.78, 0.81, and 0.99 for each evaluation period, respectively. Additionally, given the highly correlated nature of the dataset, we conducted an experimental design encompassing various preprocessing techniques and machine learning models to evaluate the main effects of each factor on prediction performance.
Retrieval-Augmented Generation (RAG) offers a robust way to enhance large language models (LLMs) with domain-specific knowledge via external information retrieval. In banking—where precision, compliance, and accuracy are vital—optimizing RAG is crucial. This study explores how various document parsing, chunking, and indexing techniques influence the performance of RAG systems in banking contexts. Our evaluation framework measures their effects on retrieval accuracy, contextual relevance, and output quality, offering practical insights for building more reliable and effective RAG solutions.
Purpose: Industrial applications increasingly rely on complex predictive models for process optimization and quality improvement. However, the relationship between statistical model performance and actual operational benefits remains insufficiently characterized. This research investigates when model complexity provides genuine business value versus statistical over-engineering.
Methods: We systematically compare machine learning and deep learning models against simpler statistical approaches across varying levels of process noise and measurement uncertainty. The analysis integrates predictive modelling with simulation-based optimization to evaluate both technical accuracy and operational impact in manufacturing and service environments.
Key Findings: Complex models demonstrate superior prediction accuracy under controlled conditions but show diminishing operational advantages as system variability increases. The study quantifies critical noise thresholds across multiple case studies where statistical sophistication becomes operationally irrelevant, challenging conventional statistically-based model selection criteria.
Innovation: This research uniquely bridges predictive analytics and industrial statistics by measuring the gap between model evaluation metrics and business outcomes across different uncertainty levels. We provide empirical evidence for when simple statistical models deliver equivalent operational performance to complex alternatives.
Practical Impact: The findings offer practitioners a statistically-grounded framework for model selection based on process characteristics and operational context, preventing over-investment in unnecessarily complex analytical solutions while maintaining performance standards.
Statistical Process Control (SPC) and its numerous extensions/generalisations focus primarily on process monitoring. This permits identification of out-of-control signals, which might be isolated out-of-control observations or a more persistent process aberration, but says nothing about remedying or controlling them. While isolated out-of-control signals require isolated interventions, a more persistent process deficiency requires more effort to return the process to target. Feedback adjustment involves statistical procedures which aim to improve a process that is subject to deterioration. In its simplest form, feedback adjustment proposes forecasting future values of an unstable process and making adjustments that turn the process back onto target.
In the first part of the presentation, we will review some of the more commonly used feedback adjustment procedures. In particular, we shall discuss the popular exponentially weighted moving average (EWMA) scheme with some of its extensions. These include the effect of adjustment on a perfectly on-target process and selective adjustment to minimise adjustment costs.
In the second part, we will discuss in more detail some of the restrictive assumptions that are made by traditional feedback adjustment techniques and suggest how they might be relaxed. For example, it is commonly assumed that there exists only one compensatory variable that can be changed to adjust the process, that the system is responsive (i.e., changes made take full effect before the next observation), and that the process gain is known. Relaxing these assumptions is required before feedback adjustment can be applied to modern manufacturing problems.
Many chemometrics methods like Principal Component Analysis (PCA) function under the assumption of time independent observations, which may not be valid in most industrial applications. This is particularly true when PCA is employed for multivariate statistical process control. To handle time dependent data, Dynamic PCA (DPCA) has been proposed, which incorporates expanding the feature matrix with lagged versions of itself to capture time-dependent relationships. This however introduces challenges such as selecting the number of lags as a hyperparameter and the interpretation of the latent structures as they are potentially composed of numerous features including their lagged versions. In this paper, we investigate the means for proper selection of the number of lags based on the autocorrelation structure of the original features and clearer understanding of the contributions of these features and their lagged versions in the latent variables through regularization.
Distribution-free (also known as nonparametric) control charts have been shown to be useful for on-line monitoring of lot production within a finite horizon production (FHP) process. Despite the partial process knowledge at the beginning of production in a FHP process, a distribution-free control chart can be started without any restrictive assumption about the underlying distribution of the quality characteristic. In this work, three nonparametric Shewhart-type control charts are investigated to monitor the unknown scale parameter in FHP processes based on some well-known nonparametric tests for scale. To this end, the violation of the assumption of equal medians of the reference and the test population distributions is investigated and a fourth control chart based on the Moses test, which does not require this assumption, is considered. An extensive numerical analysis is performed to examine chart performance based on some metrics suitable in the FHP setting. A real industrial example is presented to show a practical implementation of the investigated charts. Conclusions and future research ideas are provided.
Design of experiments (DoE) is a cornerstone methodology for optimizing industrial processes, yet its application to multistage processes remains underdeveloped, particularly in cost-constrained contexts. We present a methodology for cost-efficient experimental design tailored to such contexts, illustrated through a case study in potato fry production.
Potato fry production involves a series of interdependent stages. This study examines three critical stages: the two boiling steps and the frying step. Temperature and residence time are the key factors studied in each of these stages, as they not only significantly impact product quality but also determine the time required for each run of the production process. Notably, cooling transitions take longer than heating, and residence time defines the run length, making time the primary constrained resource.
Our approach integrates DoE principles with optimization algorithms to generate designs where run costs vary dynamically based on selected factor levels, creating experimental designs that maximize resource efficiency without compromising statistical efficiency. Moreover, these designs offer enhanced adaptability to the unique requirements of diverse experimental settings, thereby accelerating the integration of DoE into multistage industrial applications.
Our preliminary results demonstrate substantial gains in cost-efficiency and statistical performance, evidenced by optimized budget utilization and enhanced precision in parameter estimation. Our ongoing research focuses on validating and further developing this methodology at the UGent Veg-i-Tech pilot plant and with the support of the Belgian potato industry. Beyond food production, our methodology offers broad applicability to industries with variable run costs, such as chemical manufacturing, energy production, and pharmaceutical development.
ESBELT, a manufacturer of conveyor belts, was preparing to replace a critical machine in its production line and aimed to ensure a robust technology transfer. The machine fused multiple textile layers using a specific combination of temperature, air flow, tension and speed. Product quality was primarily evaluated by layer adherence, a critical-to-quality characteristic assessed destructively in the lab.
To support the redesign of the new machine, we conducted a sequential design of experiments (DoE) to gain a deeper understanding of the process. The project faced numerous practical challenges, including experimental constraints, measurement limitations, and short-term process variability. In this talk we will share the strategy used to structure the experimentation, the tactics applied to overcome obstacles in setup and execution, and the key learnings that emerged along the way.
The investigation followed a structured 10-step methodology aligned with statistical engineering principles. This included defining the problem and objectives, mapping the system, assessing measurement variability, identifying potential control and noise factors, considering design options under constraints, selecting and executing an appropriate experimental plan, and analyzing and interpreting the results to support decision-making.
This presentation offers a real-world application of DoE in an industrial setting, illustrating how careful experimental planning and flexibility in execution delivered valuable insights. The project ultimately resulted in a clearer understanding of the process and provided actionable input for equipment redesign and enhanced process monitoring.
Well microplates are used in several application areas, such as biotechnology, disease research, drug discovery and environmental biotechnology. Within these fields, optimizing bioassays such as CART-T, ELISA and CRISPR-Cas9 is commonplace. Microplates have a fixed size, and the most used ones have 24, 48, 64, 96, 384 or 1,536 wells, with each well representing an individual experiment. When designing an experiment for microplates, it is necessary to consider positional effects. These effects include row/column effects (due to dispensing or reading results) and edge effects (due to different thermal conditions at the edges). Additionally, factors that are difficult to change may be present when several microplates are used in one experiment. OMARS designs are a cost-efficient family of experimental designs that enable the study of a large number of factors at reduced cost. One example of a design in the OMARS family is the Definitive Screening Design. In this talk, we will explain how we devised an algorithm using an integer programming approach to concatenate OMARS designs that minimizes the correlation between effects, and how such a design can be blocked efficiently in the presence of several random effects. We will present results for 96, 384, and 1,534 wells, both with and without perimeter wells, and compare them with optimal design procedures and designs from the literature. We will demonstrate the application of these designs through examples of bioassay optimization.
Timely crop yield estimation is a key component of Smart Agriculture, enabling proactive decision-making and optimized resource allocation under the constraints of climate variability and sustainability goals. Traditional approaches based on manual sampling and empirical models are constrained by labour intensity, limited spatial coverage, and sensitivity to within-block (-site) heterogeneity. Smart Agriculture leverages digital technologies, geospatial data, temporal data and predictive models to monitor and manage crops in a site-specific and data-driven manner. In this context, image analysis and CNN architectures are powerful tools for yield prediction with high-resolution imagery which, however, requires expensive acquisitions and often lacks in historical databases. This study proposes a scalable, data-driven framework for yield prediction based on Time Series Extrinsic Regression (TSER) algorithms. The modelling approach exploits multi-temporal medium-resolution imagery from Sentinel-2 satellite to extract, across the growing season, block-specific temporal statistics of vegetation indices (e.g., NDVI). The adopted approach is acknowledged to be robust to sensor noise, intra-block variability and geolocation inaccuracies which are common challenges in medium-resolution satellite data. The predictive framework is further enriched with site-specific crop management data, allowing the model to account for structural (e.g., plants density) and phenological variability (e.g., cultivar-dependent ripening time). The proposed strategy leverages freely accessible and temporally consistent Sentinel-2 archives, enabling retrospective modelling over multiple seasons. Results from a comparative evaluation conducted across multiple state-of-the-art TSER algorithms show that the best-performing TSER models achieve predictive performance comparable to image-based predictive strategies, while offering substantial advantages in terms of computational efficiency, and operational scalability.
The IFP group is a leader in research and training in the energy and environmental sector, particularly in the development and commercialization of catalysts. Building accurate predictive models for these catalysts usually requires expensive and time-consuming experiments. To make this process more efficient, it’s helpful to leverage existing data from previous generations of catalysts. This is where transfer learning comes, as it allows knowledge gained from modeling older catalysts to be applied to new ones, improving accuracy and reducing the need for large amounts of new data. A first attempt using a Bayesian transfer approach demonstrated promising results: it lowered both development time and cost by transferring data and models from a previously studied fossil-based catalyst (the source) to a new one from the same fossil domain (the target). However, this approach assumes that the models for the source and target catalysts share the exact same structure, which can be a limiting factor. In contrast, this work investigates heterogeneous transfer learning strategies, where the target model includes an extra feature and parameter. Two cases are studied, with and without knowledge of the target model structure. In both settings, the proposed heterogeneous transfer learning techniques achieve good performance on synthetic data sets.
Manual Welding is an important manufacturing process in several industries such as marine, automotive and furniture among others. Despite the widespread welding, it still causes a significant percentage of rework in many companies, especially small to medium sized companies. The objective of this project is to develop an economic online monitoring method for detecting defective welds using machine learning techniques. This will be done by monitoring the current consumption and weld temperature during welding. Despite the limited sample size, results suggest that SVM provide a promising 93% accuracy in detecting surface defects. The proposed method was implemented at a small ornamental fabrication company and demonstrated economic feasibility.
Turboprop engines undergo regular inspections, yet continuous analysis of in-flight sensor data provides an opportunity for earlier detection of wear and degradation—well before scheduled maintenance. The choice of statistical method plays a crucial role in ensuring diagnostic accuracy and interpretability. In this study, we compare the performance of traditional parametric methods—specifically regression models—with a nonparametric, depth-based functional data approach for anomaly detection. We evaluate each method’s ability to identify deviations in engine behavior that may signal early-stage faults or potential sensor errors. Using a real-world engine performance dataset, we assess the sensitivity, applicability at different stages of the diagnostic analysis, and practical interpretability of both approaches. The results offer recommendations for applying these methods in safety-critical aircraft engine condition monitoring.
The power curve of a wind turbine describes the generated power as a function of wind speed, and typically exhibits an increasing, S-shaped profile. We suggest to utilize this functional relation to monitor the wind energy systems for faults, sub-optimal controls, or unreported curtailment. The problem is formulated as a regression changepoint model with isotonic shape constraints on the model function, and we devise a multiscale segmentation scheme which is able to detect both small and persistent deviations as well as short-lived anomalies. The application to real generation data as well as a simulation study illustrate the benefits of the methodology.
Electric batteries are often connected in parallel to ensure a wider power supply range to external electrical loads. Their condition is routinely monitored through the current measured when the batteries supply power. When the condition is adequate, the current is balanced throughout the system, with each battery contributing equally to the electrical load.
To ensure that monitoring focuses on the relative contributions of each battery rather than the total electrical load, we propose a statistical process monitoring (SPM) approach based on compositional data. We demonstrate that the proposed approach can maintain a controlled false alarm rate across varying total electrical loads. Its practical applicability is illustrated through a case study in the SPM of parallel-connected nickel-cadmium batteries installed on a modern high-speed train fleet to power auxiliary onboard systems.
Funding Details
The research activity of C. Capezza, A. Lepore, and E. Rossi was carried out within the MICS (Made in Italy – Circular and Sustainable) Extended Partnership and received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR) – MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.3 – D.D. 1551.11-10-2022, PE00000004). The research activity of B. Palumbo was carried out within the MOST - Sustainable Mobility National Research Center and received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR) – MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.4 – D.D. 1033.17-06-2022, CN00000023). This work reflects only the authors’ views and opinions, neither the European Union nor the European Commission can be considered responsible for them.
Statistical consulting plays a crucial role in bridging theory and practice across industries and research. This session brings together professionals with diverse consulting backgrounds—including a freelance consultant, a consultant from a small firm, a consultant from a large organization, and an internal statistical consultant—to explore what it takes to succeed in the field today and in the near future.
We propose a dynamic round table discussion structured around key themes such as the essential skills required in different consulting roles, strategies for lifelong learning, and the challenges involved in recruiting or mentoring new professionals. Panelists will also share their approaches to managing projects effectively and reflect on how their work has changed in the past years, as well as what trends they anticipate in the next ones.
The session aims to highlight both commonalities and differences across consulting contexts while actively engaging the audience in reflection and dialogue. By sharing practical experiences, challenges, and strategies, both panelists and attendees will contribute to a collective understanding of how statistical consulting is evolving. Ultimately, the goal is to support current practitioners and inspire future consultants by offering valuable insights, encouraging peer exchange, and fostering meaningful connections—whether participants are just starting out or bring years of experience to the table.
Metrology is the science of accurate, reliable and traceable measurements with results expressed in the internationally recognized SI system of units. EMN Mathmet is the European Metrology Network for Mathematics and Statistics, offering a platform for exchange, cooperation and strategic planning for mathematical and statistical experts working at European national metrology institutes (NMIs) and designated institutes (DIs). Mathmet’s vision is to ensure quality and trust in algorithms, software tools and data for metrology, and in inferences made from such data, to foster the digital transformation, industrial competitiveness, climate change mitigation, health and environment safety, energy and society sustainability. In recent years, Mathmet published a Strategic Research Agenda, a set of Quality Assurance Tools for data, software and guidelines, an overview Report on existing guidelines, software tools and reference data, and organized a Measurement Uncertainty Training Activity, all of which can be found at the Mathmet website https://www.euramet.org/european-metrology-networks/mathmet.
In this conference session, mathematicians and statisticians from Mathmet would like to exchange ideas with the wider maths & stats community on the topic of trustworthy measurements and quality assured data, and the methods and tools required for this. After a general introduction of EMN Mathmet, two case studies will be presented. The first case study relates to a recently started project that focuses on validating both classical and AI-based algorithms which can be used to predict power flows and unwanted events in the electrical grid. In the second case study, the application of Bayesian methods in metrology, e.g., for analysing interlaboratory comparison data or other measurement data, is discussed.
In both case studies, the main challenges will be presented and an active interaction and discussion with the audience will be appreciated. The session will round up with some concluding remarks by the chair of EMN Mathmet.
Convex hulls represent a powerful geometric tool with broad applications in multivariate data analysis and statistical process monitoring. In this work, we introduce two methodologies that leverage convex hull properties for anomaly detection, change tracking in complex systems, and enhancement of the sensitivity of classical process control charts. Experimental results indicate that the proposed approach achieves excellent performance in the early detection of deviations, positioning it as an innovative tool for advanced statistical monitoring in domains such as industrial production, healthcare, and security systems.
In this work, we study the behavior of nonparametric Shewhart-type control charts, which employ order statistics and multiple runs-type rules. The proposed class of monitoring schemes include some existing control charts. In addition, new distribution-free monitoring schemes that pertain to the class, are set up and examined extensively. Explicit expressions for determining the variability and the mean of the run length distribution for the enhanced control charts are additionally delivered. As an example, a real life managerial application is considered, where the proposed framework is implemented in order to enhance the provided services of a company under a supply chain management environment. Based on numerical comparisons, we draw the conclusion that the new charts outperform their competitors in identifying potential changes in the fundamental distribution in almost cases considered.
The focus on every experimental process is observing, studying and understanding phenomena, which are of multivariate nature. The rapid growth of computational power, in combination with the existence of different statistical packages, has facilitated the data collection and led to the development of statistical techniques for monitoring and surveillance. In real world settings, the characteristics under study are correlated with each other and are often comprised of both interval/ratio scale measurements and categorical (ordinal/nominal) variables, especially when the data sets are collected from clinical experience.
In the present work, we first introduce a class of multivariate semiparametric control charts for the simultaneous monitoring location, scale or both, which exploits the theory of order statistics, concomitants and copulas. Key features of the new schemes include: the identification of the characteristic(s) under study which triggered an alarm, and whether the alarm was triggered because of a mean or a variance shift, extension to higher dimensions, and almost purely nonparametric behavior.
Furthermore, we introduce a novel, machine learning, and artificial intelligence monitoring procedure for the joint surveillance of quantitative and qualitative variables, which leverages the idea of clustering to the traditional statistical process control. The advantages of these charts are their ability to harness high dimensional, mixed-type data, their semiparametric nature, the fast convergence and robustness of the algorithmic procedure.
Finally, the evaluation of the performance of all the proposed control charts is discussed, and their implementation is demonstrated using real-world data sets, mainly from the area of biostatistics.
This work presents a novel active learning market framework that enhances both forecasting accuracy and parameter estimation quality in data-constrained environments—typical in many industrial and business applications. Traditional models often rely on full data access, but our approach prioritizes selective acquisition of high-value data, striking a balance between statistical efficiency and operational cost.
We develop both batch-mode strategies for one-time data acquisition and online adaptive methods that enable real-time decision-making. Our framework integrates market-based mechanisms—capturing willingness-to-pay and willingness-to-sell—to guide data selection, and applies exponential forgetting to adapt models efficiently over time.
Empirical evaluations in energy forecasting and demographic modeling scenarios demonstrate improved performance in both predictive accuracy and estimation stability, while significantly reducing data costs. The approach scales to multi-agent settings, making it versatile across sectors such as energy, finance, and industrial analytics.
This research contributes a statistically principled, cost-effective solution for optimizing data acquisition, supporting smarter decisions in real-world forecasting and modeling tasks—aligned with ENBIS goals of improving business and industrial statistics through innovative applications.
Healthcare fraud is a significant issue that leads to substantial financial losses and compromises the quality of patient care. Traditional fraud detection methods often rely on rule-based systems and manual audits, which are inefficient and lack scalability. Machine learning methods have begun to be incorporated in the fraud detection systems of insurance companies; however these methods mainly focus on tabular data. However, each claim may also be accompanied by a wealth of unstructured textual data, such as hospitalization summaries, medical opinions, clinical notes, surgical operation reports and discharge papers. These provide a fertile ground for the application of Natural Language Processing (NLP) methods. Transformer architectures have been at the forefront of research in NLP and Deep Learning in general. Language models specific to the medical domain have been recently introduced, for example BioBERT and BioGPT. In this paper, we leverage traditional NLP techniques like Topic Modeling in addition to the newest advances in transformers to create a framework for detecting diseases concerning each case by extracting information from the available unstructured data. This framework can then be used as a fraud detection system by checking if the extracted information is consistent with the information contained in the claim.
Modern industrial systems generate real-time multichannel profile data for process monitoring and fault diagnosis. While most methods focus on detecting process mean shifts, identifying changes in the covariance structure is equally important, as process behavior often depends on interdependence among multiple variables. However, monitoring covariance in multichannel profiles is exacerbated by the high dimensionality and unknown, possibly sparse, shift patterns.
We address these problems by leveraging functional graphical models to represent conditional dependencies among profiles and enable interpretable monitoring. The proposed approach combines penalized likelihood ratio tests with varying penalties to adapt to diverse covariance changes. A diagnostic procedure based on change-point detection then identifies which relationships have shifted. A simulation study and a real-world case involving temperature profile monitoring are carried out to demonstrate the method’s effectiveness and practical applicability.
Acknowledgments
The research activity of C. Capezza, D. Forcina, and A. Lepore was carried out within the MICS (Made in Italy – Circular and Sustainable) Extended Partnership and received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR) – MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.3 – D.D. 1551.11-10-2022, PE00000004).
The research activity of B. Palumbo was carried out within the MOST - Sustainable Mobility National Research Center and received funding from the European Union Next-GenerationEU (PIANO NAZIONALE DI RIPRESA E RESILIENZA (PNRR) – MISSIONE 4 COMPONENTE 2, INVESTIMENTO 1.4 – D.D. 1033.17-06-2022, CN00000023).
This work reflects only the authors’ views and opinions, neither the European Union nor the European Commission can be considered responsible for them.
We are living in a new era of digitalization, where there is a prevailing belief that, due to the sheer volume and speed at which data is generated, emerging technologies based on artificial intelligence are now capable of solving major problems across various domains (finance, society, industry, healthcare, etc.) solely through the analysis of empirical data—without the need for scientific models, theory, experience, or domain knowledge. The idea is that causality no longer matters; only simple correlation does. Some even go so far as to claim that Statistics is dead, having been rendered obsolete by the rise of Data Science. They view Statistics as outdated and statisticians as overly specialized professionals, skilled in techniques that are no longer useful and concerned with issues that seem irrelevant given the complexity of 21st-century challenges.
In this talk, I will attempt to shed light on the reasons behind these beliefs and share my perspective on the key factors that could help Statistics regain its societal recognition and its critical role as a key component in successfully addressing many of the problems facing our society. Most of these insights come from the teachings of Professor George EP Box, who has been one of the most influential people in my professional career.
In particular, I will address the potential of Latent Variables Multivariate Statistical Models to address some of the key challenges in Industry and Health 4.0. Among these, I will highlight the development of imaging biomarkers for early cancer diagnosis using non-orthogonal PCA, as well as constrained process optimization, raw material design space definition, and the development of a latent space-based multivariate capability index using historical data via Partial Least Squares (PLS) Regression. These approaches leverage the ability of PLS to model causality in latent space, even from historical data, which is characteristic of these highly digitalized environments.
An approach to the construction of Balanced Incomplete Block Designs (BIBD) is described. The exact pairwise balance of treatments within blocks (second-order balancing condition) is required by standard BIBD. This requirement is attainable when $\lambda = b \binom{k}{2} / \binom{t}{2}$ is an integer, where $t$ is the number of treatments, $b$ is the number of blocks and $k$ is the block size.
This work presents an algorithm for generating BIBD with particular attention to settings where a second blocking variable is taken into account (Youden squares) and the blocks are assigned to $s$ groups (sessions) where all treatments are equally represented inside each one.
Two real-world applications are presented. The first refers to an exploratory experiment with 8 two-level factors leading to $t$=20 trials, assessed by $k$=4 evaluators through $b$=20 blocks divided into $s$=4 balanced sessions. The second example refers to a robust design experiment based on a Central Composite Design involving 4 technological and 2 environmental factors leading to $t$=30 trials, evaluated in $k$=5 environmental conditions within $b$=30 blocks divided into $s$=5 balanced sessions. In these experimental settings, the second-order balancing condition is not attainable since $\lambda$ is not an integer.
The proposed algorithm has been designed to approximate this condition as closely as possible, maintaining the first-order balancing condition.
The implementation of the algorithm has been implemented in the R environment.
As a reference frame, balanced factorial designs are used in this presentation, because these designs are orthogonal for all linear models, they can be used for. Orthogonality means that the experimental factors are mutually orthogonal (angles of 90◦) and as such are independent and not correlated. As a consequence, the parameters of the fitted linear models are also independent, leading to straightforward interpretations of the parameters and increasing knowledge about the factors of influence on the system under study. If the primary interest is an as accurate as possible estimation of the predicted response, orthogonality is not a prerequisite for optimal efficiency expressed as goodness of fit. Nevertheless, balanced factorial designs are D- and G-optimal, providing both optimal variance properties for parameter and predicted response.
Multicollinearity in experimental designs arises when designs are unbalanced or when additional constraints are imposed on the experimental factors (fi designs for mixture systems). It is generally understood that least squares estimation can lead to misleading results when the independent variables are correlated. The multicollinearity becomes harmful, when estimation or hypothesis testing is more affected by the multicollinearity among the regressor variables than by the relationship between the dependent and the regressor variables. Multicollinearity can imply incorrect signs and large variances of parameter estimates, unreliable test statistics and variable selection criteria.
Most of the time the multicollinearity structure of a design is presented by the correlation matrix (heatmap), calculated from the extended design matrix. Although in principle the correlation matrix is showing the full multicollinearity structure, the structure is difficult to interpret. This talk proposes to investigate the multicollinearity by calculating the VIF’s for each parameter to be estimated, before the experiment is caried out. Therefore, the unknown error variance of the dependent variable is put equal to 1. Next, the design matrix (X) is centered and scaled to unit length (W), to eliminate the effect of different coding on the calculations . As a result, the correlation matrix of the design can be calculated as W’W. Since the VIF’s are equal to the head diagonal of the (W’W)-1 matrix, a SVD on the W matrix (W=ULV’) results in the VIF’s to be equal to the diagonal of V’L-2V. Or on a per parameter basis each VIFi can be decomposed into a sum of components, each associated with one and only one singular value.
With p the number of columns in X and W and thus the number of parameters to estimate, i the ith parameter, j the jth singular value. This decomposition shows how much one or more small singular values will inflate the parameter estimates. The corresponding eigenvectors of these small singular values are defining multicollinearity constraints as orthogonal linear combinations in the original centred and scaled experimental factors (W). As a consequence, the experimental factors that are most important in defining the multicollinearity can be investigated by evaluating the Principal Components of the W’W matrix with the smallest corresponding eigenvalues.
Some examples of balanced and unbalanced factorial designs, as well as mixture designs are explored to demonstrate the theory.
Bayesian Optimization (BO) has received tremendous attention for optimizing deterministic functions and tuning ML parameters. There is increasing interest in applying BO to physical measurement data in industrial settings as a recommender system for product/process design. In this context multiple responses of interest are the norm, but "basic" BO is only defined minimization/maximization of a single response. In this presentation we introduce "Bayesian Desirability Functions" (BDFs), which simplify multiple response optimization back into a simpler single response optimization problem. We will demonstrate that BDFs are also a natural approach to matching response targets and batch augmentation of two or more runs.
In this work, we address the problem of binary classification under label uncertainty in settings where both feature-based and relational data are available. Motivated by applications in financial fraud detection, we propose a Bayesian Gaussian Process classification model that leverages covariate similarities and multilayer network structure. Our approach accounts for uncertainty in the observed labels during training, enabling robust inference and reliable out-of-sample prediction. We define a composite covariance function that integrates kernel representations over both covariates and network layers, effectively capturing different modes of similarity. To perform posterior inference, we use a first gradient marginal Metropolis-Hastings sampler, which improves sampling efficiency and reduces the need for tuning. The proposed methodology is validated on simulated data and applied to a real-world financial fraud detection task, demonstrating strong practical applicability with real financial data
Early process development in biopharma traditionally relies on small-scale experimentation, e.g. microtiter plates. At this stage, most catalyst candidates (clones) are discarded before process optimisation is conducted in bioreactors at larger scales, which differ significantly in their feeding strategies and process dynamics. This disconnect limits the representability of small-scale experiments, potentially overlooking critical interdependencies between clones and process conditions (1). To address these challenges, we introduce a multi-fidelity batch Bayesian optimisation framework that integrates a computational bioprocess model and variable-scale experimentation to improve decision-making in bioprocess development.
A key component to test the framework is a scale-aware process model for Chinese hamster ovary cells, adapted from Craven et al. (2). It captures clone-specific behaviours and simulates challenges in scaling up to pilot-scale reactors in biopharma (Figure 1). By incorporating noise, feeding strategies, and kinetics, the model generates in silico data that reflect realistic experimental conditions across scales.
Next, we test our Bayesian optimisation framework using this in silico data. Crucially, we extend traditional optimisation by dynamically selecting both experimental scales (multi-fidelity) and batch sizes, enabling efficient exploration of the design space. In two case studies, we highlight improvements in cost efficiency and product titres, specifically compared to classical experimental designs. Our results show that integrating multi-scale data early in development leads to more robust process outcomes with fewer experiments.
Overall, this work presents a systematic screening strategy that moves beyond heuristic-driven approaches to reduce experimental burden, lower development costs, and support more informed scale-up decisions in bioprocess development.
(1) Hemmerich, J., Noack, S., Wiechert, W., & Oldiges, M. (2018). Microbioreactor systems for accelerated bioprocess development. Biotechnology journal, 13(4), 1700141.
(2) Craven, S., Shirsat, N., Whelan, J., & Glennon, B. (2013). Process model comparison and transferability across bioreactor scales and modes of operation for a mammalian cell bioprocess. Biotechnology Progress, 29(1), 186-196.
Statistical modelling of material fatigue supports the development of technical products to achieve a design which reliably withstands field load but avoids over-engineered and further unnecessary weight, energy consumption, and consequently, life cycle costs. In this relation, the process of statistical modelling contains test planning, model selection as well as parameter estimation. Several combinations of methods for test planning as well as analysis have been compared and treated as different measurement instrument with respect to the detection of the failure-free load level. The accuracy of the failure free level has been decomposed into trueness and precision to detect potentially biases of the investigated methods more specifically. The results of the uncertainty measurements have been combined with aspects of effort into a desirability function which allows to tailor the selection of an appropriate case-specific combination of planning and analysis methods. An application example is shown based on material data from an engine component.
References:
Haselgruber, N., G. Oertelt and K. Boss (2025): Comparison of Material Fatigue Testing Strategies regarding Failure-Free Load Level of Steel Specimens using Bootstrapping and Statistical Models. Procedia Computer Science 253 (323-335). Elsevier Publishing: 10.1016/j.procs.2025.01.095.
Balanced systems are widely employed across various industries and are often exposed to dynamic environments. While most existing research emphasizes degradation dependence, this study focuses on optimizing maintenance strategies for balanced systems by jointly considering dependent competing risks and environmental influences. System failure is defined under three conditions: (1) soft failure; (2) hard failure; and (3) imbalanced failure. To capture environmental impacts on component degradation, we adopt a Lévy process that integrates a gamma process, compound Poisson shocks, and an embedded Markov chain. Maintenance decisions, including do-nothing, repair, and preventive replacement, are made at periodic inspection epochs. The problem is formulated as a Markov decision process (MDP) and solved using both value iteration and a Dueling Deep Q-Network (DQN) algorithm. A flap system case study, along with a thorough sensitivity analysis, illustrates the efficacy of the proposed methodology and highlights the benefits of proactive maintenance in harsh environments.
Aerospace industry is driven by the need to develop new concepts and methods to handle the constraints of weight and performance efficiency, reliability, regulatory safety compliance, and cost-effectiveness. In parallel to these demands, engineers have to manage increasing design complexity by Multi Disciplinary models and accelerate the product development cycles to be able to fulfil the market demands.
In this work it is presented how robust design computations can be performed by using analytics by probabilistic VMEA as a complement to existing algorithm in a computational workbench. When this analytics approach is used, a more efficient recording of design margins can be gained as well as time efficiency can be improved.
Last year I gave my quite classical DoE course again to my colleagues, and realised that teaching the design construction is actually not the most useful time spent for practitioners, as modern software takes care of that for the practitioners needs. I had had the feedback before that the most valuable piece in my course was the section on understanding the problem at hand, identifying the response(s) and influencing factors. A second observation I made at the JMP Discovery Summit Europe was that most practitioners using DoE there were coming from typical science backgrounds or companies with a strong science foundation, less engineering and certainly not any marketing or similar. Based on these observations I will present my ideas about a renewed practitioners DoE course, and also different communication about DoE to get a broader audience interested.
My essential idea is to spent more time on the very practical aspect on understanding the problem, what is already known, and how to ensure that the execution of the experiment is going to plan. One important change is also to introduce the practitioners to the big toolbox that is available in modern design of experiments. Finally, it is also all about, what you can and cannot infer from the analysis.
What are your ideas about teaching DoE? Do you recognise my observations?
There are typically three approaches to using statistical software in teaching. The first is to teach the statistical topic at hand without any use of software, then show how to apply methods using statistical software. This separation approach follows the idea that instruction should be software neutral. While a statistical topic is broader than a particular method, including ideas and principles, by nature this common teaching approach often focuses narrowly on methods. Multiple examples and simulations are sometimes used to address this problem.
The second approach is to open the software and then teach the meaning of the settings and inputs in the order required by the software. Here the software itself takes the lead, and provides the motivation for learning the topic, again often with a focus on methods.
The third is more innovative: the students use the software tools in active learning exercises to explore the broad statistical topic. The pedagogical aim in this approach is to simultaneously teach the whole topic and the use of the software tools. Examples of this approach are shared and compared to alternatives.
When we use software, the two separate issues of how to use the software and how to employ good statistical practice to solve a real problem are often jumbled in the mind of the student. This additional point is also addressed.
I will present examples of how I have analysed data to display the outcome on LinkedIn and the comments on LinkedIn.
Examples, include:
• UK Gas Price rip off
• Small Boats and Slogans
• Death in England and Wales and the winter fuel allowance
I also wish to discuss two other examples including:
• Global Warming, mobile phones, the use of AI and the law of energy.
• The case of Lucy Letby. I will review the data and apply some statistic to understand the data used in the case.
I will also include a short update on the RSS18404 Six Sigma and Lean scheme and the upcoming article in Significance on Shewhart and the history of SPC to mark the 100th anniversary of SPC in 2024.
PRIM is a Bump Hunting algorithm traditional used in a supervised learning setting to find regions in the input variables subspace while being guided by the data analyst, that are associated with the highest or lowest occurrence of a target label of a class variable.
We present in this work a non-parametric PRIM-based algorithm that involves all the relevant attributes for rule generation and that provides an additional post processing step for rule pruning and organization.
Data privacy is a growing concern in real-world machine learning (ML) applications, particularly in sensitive domains like healthcare. Federated learning (FL) offers a promising solution by enabling model training across decentralized, private data sources. However, both traditional ML and FL approaches typically assume access to fully labeled datasets, an assumption that rarely holds in practice. Users often lack the time, motivation, or expertise to label their data, making labeled examples scarce.
This paper proposes a federated semi-supervised learning (FSSL) framework that learns from a small set of labeled data alongside a large volume of unlabeled data. Our approach combines FL with VIME, a leading semi-supervised learning (SSL) method for tabular data. Unlike image or text data, tabular data presents unique challenges for SSL due to the absence of transferable pretext tasks.
We evaluate our method of predicting Parkinson’s disease severity and show that it significantly outperforms both supervised and SSL baselines across varying proportions of labeled data. The model achieves an RMSE of 7.74 and an MAE of 6.26 in the most challenging setting with only 10% labeled data, substantially outperforming both supervised FL and standalone SSL baselines, demonstrating the strength of our method under limited supervision. These results show that our method effectively leverages unlabeled data to enhance predictive performance in a privacy-preserving, real-world setting.
Real-time monitoring systems play a crucial role in detecting and responding to changes and anomalies across diverse fields such as industrial automation, finance, healthcare, cybersecurity, and environmental sensing. Central to many of these applications is multivariate statistical process monitoring (MSPM), which enables the concurrent analysis of multiple interrelated data streams to identify subtle shifts in system behavior. Such systems require models that can handle high-speed data streams, deliver rapid insights, and adapt effectively to evolving conditions.
This study provides an extensive review of statistical and machine learning techniques used in real-time monitoring, with a special focus on MSPM methods and their integration with online and streaming data analysis. We classify these approaches into traditional statistical frameworks, including MSPM, online and streaming machine learning models, and deep learning-based architectures, highlighting their suitability for different monitoring contexts. Furthermore, we address system-level aspects such as edge computing, distributed architectures, and streaming data platforms.
By critically examining existing methods, we reveal current challenges, including managing concept drift, improving interpretability, and overcoming computational limitations, while outlining promising avenues for future investigation. This article aims to serve as both a comprehensive resource and a practical guide for researchers and practitioners developing intelligent real-time monitoring solutions.
The EU Digital Decade Policy Programme 2030 strongly depends on safe and reliable cutting-edge technologies, like Micro-Electro-Mechanical Systems (MEMS) sensors, that are widely used in large sensor networks for infrastructural, environmental, healthcare, safety, automotive, energy and industrial monitoring. The massive production of these sensors, often in the order of millions per week, requires costly and time-consuming calibration processes, resulting in a lack of metrological traceability and a poor assurance of their performances. Hence, it is fundamental that a systematic metrology framework for a trustworthy calibration of digital sensing technologies on a large scale is developed and implemented.
A recently proposed solution for large-scale virtual calibrations of MEMS sensors relies on a Bayesian method allowing to statistically calibrate large batches of sensors with a considerable saving in time and costs. Prior knowledge derives from the experimental (in-the-lab) calibration of a ‘benchmark’ batch, representative of the whole production process. Then, the approach involves the experimental calibration of only a small sample of sensors drawn from an unknown large batch. Combining prior and updated information, the number of reliable sensors in the entire batch is inferred, an appropriate uncertainty value is assigned to all sensors, and the overall reliability of the batch is assessed in terms of appropriate (probabilistic) metrics. The approach was validated on a batch of 100 digital MEMS accelerometers calibrated at INRiM. Strategies based on hierarchical modelling are now under development to balance the effort required in the virtual calibration and the desired level of batch reliability and uncertainty.
Estimating traffic volumes across street networks is a critical step toward enhancing transport planning and implementing effective road safety measures.
Traditional methods for obtaining traffic data rely on manual counts or high-precision automatic sensors (e.g., cameras or inductive loops). While manual counting is labor-intensive and time-consuming, fixed sensors are costly and typically limited in spatial coverage.
Recently, the widespread use of mobile sensors—such as smartphones and GPS navigation devices—has led to a growing number of approaches for inferring traffic volumes from geo-referenced mobility data.
In this paper, we propose a spatial statistical calibration method based on geographically weighted regression (GWR), which integrates precise fixed sensor counts with extensive mobile GPS data to estimate traffic flows. The methodology is adapted to the spatial network setting and demonstrated using data from the city of Leeds (UK).
The advent of Industry 5.0—characterized by its emphasis on resilient and sustainable technology integration—aims to reorient industrial production toward a more competitive model with a positive societal impact. Within this framework, the Joint Research Unit (CEMI) formed by the shipbuilding company Navantia and the Universidade da Coruña is focused on developing and validating advanced methodologies for highly accurate and precise dimensional analysis of ship components, leveraging large-scale 3D datasets captured via 2D/3D laser profile sensors.
Ship panels, which consist of welded steel plates reinforced with longitudinal stiffeners, are the fundamental building blocks in modern shipbuilding. It is critical to inspect these fabricated panels to detect any structural defects or dimensional inconsistencies that could lead to assembly issues in subsequent production stages. This work presents statistical procedures to develop a digital model of the manufactured panel and extract relevant features to assess whether it can be successfully assembled later.
Given the high precision required (0.5 mm), a 3D scanning process is employed using a set of 2D laser profile sensors, resulting in a high-resolution 3D point cloud. These point clouds often contain hundreds of millions of points, making it necessary to develop big data processing techniques. The proposed tools are being implemented in an R software package. They include dimensionality reduction methods, triangular mesh generation, and comparison against theoretical CAD models. Additionally, the tools allow for the identification of key structural components (plate surface, stiffeners, etc.) and the extraction of critical geometric measurements, primarily dimensions and positioning.
During storage chicken filets develop unwanted odours caused by volatile compounds produced by spoilage bacteria present on the surface of the products. Spoilage bacteria are not harmful but may lead to rejection by consumers. The poultry industry therefore needs to optimise the shelf life to minimise the risk of rejection by consumers to reduce food waste.
Optimisation of the estimated shelf-life requires a deep understanding of the relation between consumers acceptance, the sensory properties of the chicken filet and the microbiota present on the products. In this presentation we will discuss statistical methods for connecting consumer evaluations, sensory and microbiological data based on a shelf-life experiment conducted in three countries (Portugal, Hungary, Norway). A reversed storage design was applied. Samples were evaluated by a (semi) trained panel, consumers (N~100 per country), in addition the microbiota were measured. In this presentation survival models for estimation of shelf life will be compared with cut-off point methodology and generalised linear models for linking consumer, sensory and microbiological data. The results will play an important role in the EU funded project MICROORC which aims to develop tools for dynamic shelf-life based on predictions of microbiota of chicken
CQM is a consultancy company that has been performing projects in industrial R&D for over four decades. In recent years, we have encountered several problems of the same type: calibration or fine-tuning of a complex machine for use in a production process as soon as possible. Several aspects make that the standard Response Surface Methodology (i.e., design and perform an experiment, build a model, and optimize) is not the primary method of choice for these problems. Possible reasons for this are 1) the controllable variables are typically moved in small steps only; or 2) modelling does not start from scratch as there is historic knowledge about the model from earlier machines of the same type, or the same machine in earlier instances; or 3) important physical variables cannot be observed directly, but do occur as latent variables in a causal model . Lastly, the customer or project context may already have a preferred method in place. In the talk, we share some approaches that combine several techniques and areas to address these issues, including Bayesian optimization a.k.a. surrogate assisted optimization, causal modelling, and Bayesian models.
The real estate sector plays a significant role in shaping the urban environment and influencing carbon emissions. As the demand for environmental sustainability grows, it is crucial to understand the factors that drive real estate companies to adopt environmentally friendly policies and improve their environmental performance. This study investigates the impact of board gender diversity on adopting environmental policies and environmental outcomes, specifically greenhouse gas (GHG) emissions, in global REITs from 2017 to 2023. Using a dataset of 375 REITs worldwide, we employ regression analyses to examine the relationship between board gender diversity, measured by the percentage of female directors and the Blau index, and the adoption of environmental policies such as emissions reduction protocols, renewable energy use, waste reduction initiatives, and sustainability-linked compensation. We also investigate the effect of board gender diversity on REITs' environmental performance, measured by GHG emissions intensity. Our findings reveal a significant positive association between board gender diversity and the adoption of environmental policies in REITs. We also observe the board gender diversity’s impact on GHG emissions intensity reduction, suggesting that the impact of gender-diverse boards on environmental outcomes may be more nuanced and indirect. This study contributes to the growing literature on corporate governance and environmental sustainability by providing novel insights into the role of board gender diversity in shaping REITs' environmental policies and performance.
Real world datasets frequently include not only vast numbers of observations but also high dimensional feature spaces. Exhaustively gathering and examining every variable to uncover meaningful insights can be time consuming, costly, or even infeasible. In order to build up robust, reliable and efficient regression models, feature selection techniques have therefore become inevitable. Yet many established methods consider only a single partition of the training data, risking biased or sub optimal variable choices. This work introduces a modified forward selection strategy for feature selection executed over multiple data splits, accounting for inter variable relationships and structural variation within the data to highlight the most influential variables.
Extracting meaningful insights from vast amounts of unstructured textual data presents significant challenges in text mining, particularly when attempting to separate valuable information from noise. This research introduces a novel deep learning framework for text mining that identifies latent structures within comprehensive text corpora. The proposed methodology incorporates an initial sentence classification phase to filter out irrelevant content while preserving essential information. Following this preprocessing step, we implement a deep learning-powered Named Entity Recognition (NER) system that uses predefined feature extraction to identify and extract critical entities, transforming them into structured data formats. We validate our approach using two datasets: BioCreative II Gene Mention (BC2GM) to compare it with other established approaches, and shipping industry datasets—a real-world dataset that contains emails for orders that have been executed. The findings demonstrate that deep learning significantly enhances text mining capabilities, proving its value for extracting essential information from large-scale textual repositories.
A major challenge in the chemicals industry is coordinating decisions across different levels, such as individual equipment, entire plants, and supply chains, to enable more sustainable, autonomous operations. Multi-agent systems, based on large language models (LLMs), have shown potential for managing complex, multi-step problems in software development (Qian et al., 2023). This work investigates translating this success to the chemicals industry: a network of four swing-connected gas-oil-separation plants (GOSPs) serves as a case study, where operational planning requires a trade-off between emissions and economics.
Our multi-agent framework tackles the case study in three stages: i) initial analysis, ii) strategic selection, and iii) operational realization. First, the Optimization Agent gathers inlet feed qualities for a multi-objective optimization in Pyomo. The candidate set points are then debated by Economic and Environmental Agents, using retrieval-augmented generation to support arguments. The Decision Agent then selects the final set-point. Finally, an Operator Agent validates the feasibility using a digital twin in Aspen HYSYS.
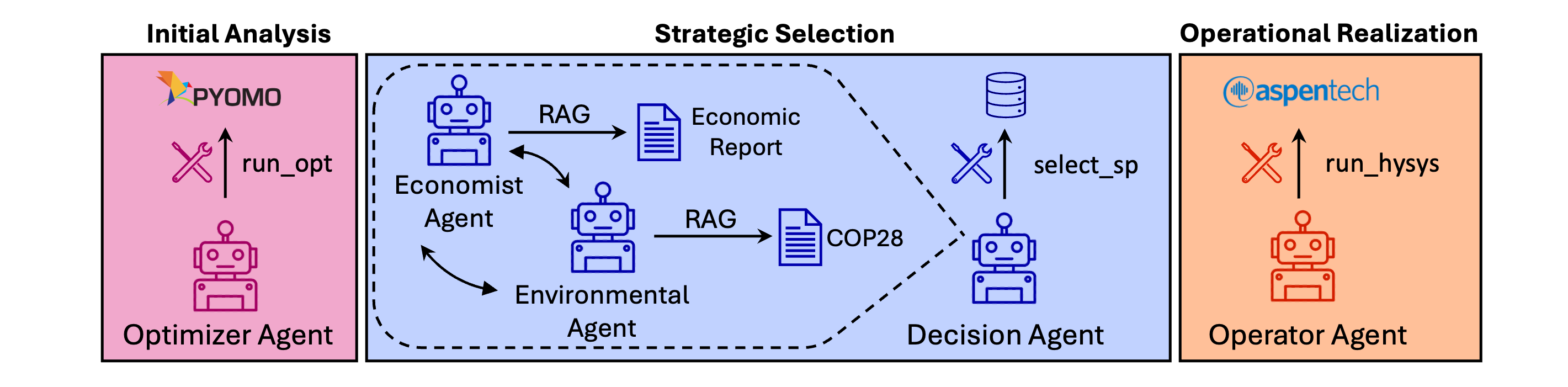
The results demonstrate how multi-agent LLMs can automate and integrate hierarchical decision-making in the chemicals industry, particularly when balancing sustainability and economic demands. While the baseline runs favour the lowest-emission strategy, imposing an economic directive led to more complex solutions, satisfying cost constraints and minimizing emissions simultaneously. The framework also outputs a rationale for its choice, enhancing transparency and explainability. Future work will consider additional agent roles (e.g., regulatory, safety), the use of reasoning models, and more, paving the way for scalable and ethical adoption of LLM-driven process automation.
The Shiryaev’s change point methodology is a powerful Bayesian tool in detecting persistent parameter shifts. It has certain optimality properties when we have pre/post-change known parameter setups. In this work we will introduce a self-starting version of the Shiryaev’s framework that could be employed in performing online change point detection in short production runs. Our proposal will utilize available prior information regarding the unknown parameters, breaking free from the phase I requirement and will introduce a more flexible prior for change-point parameter, compared to what standard Shiryaev employs. Apart from the on-line monitoring, our proposal will provide posterior inference for all the unknown parameters, including the change point. The modeling will be provided for Normal data and we will guard for persistent shifts in both the mean and variance. A real data set will illustrate its use, while a simulation study will evaluate its performance against standard competitors.
Statistical process monitoring (SPM) is used widely to detect changes or faults in industrial processes as quickly as possible. Most of the approaches applied in industry are based on assuming that the data follows some parametric distribution (e.g., normality). However, in industry this assumption is not always feasible and limits the application and usefulness of SPM for fault detection. In this presentation, a new method for univariate SPM is introduced based on permutation entropy (PE), which is a time series analysis tool that identifies unusual patterns in a series. PE is distribution-free and robust to outliers. The power of PE is illustrated using simulation study for different fault magnitudes and sample sizes. The simulation study confirms that PE can accurately detect shifts and deviations from in-control conditions in a process. In addition, the effectiveness of PE is discussed using the Tennessee Eastman process (TEP) as a case study for the detection of various types of faults. From the application of PE to the TEP, it is shown that that PE is effective in detecting faults in processes, even when there is no immediate change to the behaviour of the process. Therefore, the PE method can be applied practically to industrial processes for the purpose of fault detection.
Recent advances in the Internet of Things (IoT) and sensor technologies have provided powerful tools for the continuous, real-time monitoring of highly complex systems characterized by a wide range of features. This is particularly relevant for HVAC systems in buildings, where the objective is to maintain appropriate levels of hygrothermal comfort while minimizing energy consumption. As such, monitoring and controlling energy use, temperature, and humidity is essential for the efficient operation of any building, including shopping malls, hospitals, industrial facilities, and, of course, residential homes.
This paper presents several case studies that demonstrate the use of control charts and capability analysis to detect anomalies and manage both energy consumption and hygrothermal comfort. These case studies include applications in shopping centers, hotels, and other types of buildings. The approach ranges from traditional univariate control charts to more advanced methods where each data point is a curve (Functional Data Analysis, or FDA), as well as various multivariate techniques based on vector data.
The study incorporates both conventional statistical methods and control chart techniques developed by the authors themselves, some of which are implemented in statistical packages such as qcr.
In the planning of order picking systems, which are characterized by an increasing complexity as well as uncertainties, discrete-event simulation is widely used. It enables investigations of systems using experiments based on executable models. However, the execution of simulation experiments with different parameter configurations (simulation runs) is associated with a high level of effort. This leads us to apply methods from the Design and Analysis of Computer Experiments (DACE). The aim is to create Logistic Operating Curves (LOCs) with uncertainty bands.
Generalized Additive Models for Location, Scale and Shape (GAMLSSs) are considered as meta-models in this contribution as they allow to model the location, scale and shape parameters of a wide class of distributions. Due to this property, GAMLSSs are suitable to adequately model the complexity of order picking systems. They are employed to provide predictions for key performance indicators and can reflect the inherent uncertainties by prediction intervals.
We present an application to an example order picking system modeled with the discrete-event simulation tool AnyLogic. Key performance indicators of interest are e.g. the picking performance, the order picking accuracy and the throughput. The derivation of suitable designs of experiment as well as the development of special cases of GAMLSSs is demonstrated. Results in terms of LOCs with uncertainty bands are visualized.
In the future, GAMLSS-based meta-models will be enhanced for reference models of order picking systems to determine general systemic interdependencies.
In today’s industrial landscape, effective decision-making increasingly relies on the ability to assess target ordinal variables - such as the degree of deterioration, quality level, or risk stage of a process - based on high-dimensional sensor data. In this regard, we tackle the problem of predicting a ordinal variable based on observable features consisting of functional profiles, by introducing a novel approach called functional-ordinal Canonical Correlation Analysis (foCCA). FoCCA, routed in Functional Data Analysis, enables dimensionality reduction of observable features while maximizing their ability to differentiate between consecutive levels of an ordinal target variable. FoCCA embeds the functional signal in a suitable functional Hilbert space, and the ordinal variable in the Guttman space. This approach allows the model to capture and represent the relative differences between consecutive levels of the ordinal target while explaining these differences through functional features. Extensive simulations show that foCCA outperforms existing state-of-the-art methods in terms of prediction accuracy in the reduced feature space. A case study involving the prediction of antigen concentration levels from optical biosensor signals further demonstrates foCCA’s superior performance, offering both an enhanced predictive power and a wider interpretability compared to competing methods.
Growth curves are essential tools in biology for tracking changes in population size or biomass over time. Biological growth usually follows a sigmoid pattern, characterized by an initial slow growth (lag phase), a rapid increase (exponential or log phase), and a leveling off as they approach mature values (stationary phase and plateau). Commonly used growth models include the logistic model, generalized logistic model (Richards model), Baranyi-Roberts model and Gompertz model. The goal is often to investigate how various extrinsic factors affect growth, necessitating statistical assessment of growth curves. Comparisons are typically made visually or by univariate analysis of model parameters like lag time or maximum growth rate.
This study aims to develop a method for statistically comparing growth curves from designed experiments, assessing how experimental factors affect the shapes of the curves, and providing results that are easy to interpret and communicate to biologists. We applied ANOVA-simultaneous component analysis (ASCA) to a case study involving human muscle cells grown and continuously measured in an Incucyte® Live-Cell Analysis System. The cells were exposed to different treatments according to an experimental design. Cell growth measured at multiple time points serves as the response variables, which is modeled in relation to design factors Treatment and Dose. We compare two approaches: one where ASCA is applied directly to the raw cell growth data, and the other where ASCA is applied to the parameters derived from growth models fitted to the data.
High-grade measurement instruments as well as low-grade sensors are usually calibrated and/ or tested by means of comparison of their readings with indications of more accurate reference instruments during a period of time which is larger than the averaging time and reporting period of each of the involved instruments. As a consequence, classical uncertainty evaluation methods for assessing the calibration uncertainty explicitly or implicitly use this assumption.
However, mobile sensors for assessing the air quality, measuring, e.g., the PM- or the NO2-concentration in ambient air while mounted on a car or bike, may only be shortly collocated with an air quality station with reference instrumentation. The reporting rate of the reference station may be only 1 reading every 15 minutes or every hour, whereas the sensors may report a reading every minute or even faster, and, more importantly, the co-location time may only be in the order of 1 minute. Still, such short co-locations may provide valuable information with respect to the correct working of the sensor.
In this proposed contribution we will look at the uncertainty evaluation for such situations. We model the measurand (the quantity to be measured) by a Gaussian process and calculate the uncertainty of the difference between two reported values that are based on different average times. We apply the proposed method to datasets containing simulated and real measurement data.
In manufacturing, output of a measurement system is often used to classify products as conforming or noncorforming. Therefore, to ensure product quality, it is essential to utilize a suitable measurement system. In this regard, practitioners frequently employ various performance metrics to assess measurement systems, which are typically obtained through off-line studies involving experimental setups. However, a measurement system may fail online, during use in manufacturing, and the analyst might unknowingly continue to rely on the measurement system. As a result, online monitoring of the measurement system becomes crucial, particularly in manufacturing environments that require high-precision measurements.
In this study, we propose a real-time measurement system monitoring method. Unlike the traditional approaches for Gauge R&R studies, performance metrics are monitored in real time using statistical transformations and control charts. The real-time Gauge R&R application provides immediate feedback on measurement system, thereby enabling the early detection of potential problems. The proposed model is tested by computer simulations and it offers statistical insights for practitioners seeking to maintain high measurement reliability during ongoing production.
As more and more new materials (like raw earth, hemp concrete, etc) are used in the construction of building walls, their thermal resistance needs to be evaluated, not only at the laboratory scale, but also and more importantly in situ, at the building scale where potentially used in conjunction with other materials. A dedicated experimental prototype device limiting the influence of external weather conditions was designed within the French ANR RESBIOBAT project to produce surface temperatures and fluxes measurements to be used in an inversion procedure. However, classical inversion procedures may be limited by their capacity to handle uncertainty sources and by the prohibitive cost of the direct models used to reproduce complex physical phenomenon due e.g. to the presence of humidity in the wall and 3D effects.
This work investigates the use of multifidelity approaches in a Bayesian inversion framework to estimate the thermal resistance of opaque building walls. The approach combines low-fidelity models such as simplified thermal simulations with high fidelity thermal or hygro-thermal models. Utilizing Gaussian Process based surrogates of codes, this multifidelity Bayesian modeling technique allows for the integration of multiple sources of information with quantified uncertainties, enabling more robust and efficient parameter inference compared to conventional single-fidelity approaches. Posterior distributions of thermal resistance are computed, providing not only point estimates but also credible intervals that reflect both measurement and model uncertainties. This approach offers a promising direction for in-situ thermal characterization, particularly for new building materials and systems that challenge standard testing methods.
Mixed effect regression models are statistical models that not only contain fixed effects but also random effects. Fixed effects are non-random quantities, while random effects are random variables. Both of these effects must be estimated from data. A popular method for estimating mixed models is restricted maximum likelihood (REML).
The Julia programming language already has a state-of-the-art package, MixedModels.jl, for estimating these effects using REML. Inference for the effects is, however, based on large sample approximations or on bootstrapping.
When working with a small sample, the asymptotic approximation might not hold, and the resampling in the bootstrapping procedure might make the model inestimable.
Alternative small sample inference approaches have been suggested by Kenward and Roger [1] and by Fai and Cornelius [2]. In these methods, the asymptotic results for confidence intervals and hypothesis tests are adjusted to account for finite sample sizes. MixedModelsSmallSample.jl implements these small sample adjustments for models estimated by MixedModels.jl.
These adjustment methods have already been incorporated in many statistical software programs, such as SAS, JMP and lmerTest [3-5]. These packages, however, differ in some statistical details. For example, SAS and JMP use the observed Fisher information matrix for variance components, while lmerTest uses the expected Fisher information matrix. MixedModelsSmallSample.jl provides user options to configure these technical details, such that results from SAS, JMP and lmerTest can be exactly reproduced and easily compared.
The documentation of MixedModelsSmallSample.jl can be found on:
https://arnostrouwen.github.io/MixedModelsSmallSample.jl/dev/
References:
[1]: Kenward, Michael G., and James H. Roger. "Small sample inference for fixed effects from restricted maximum likelihood." Biometrics (1997): 983-997.
[2]: Hrong-Tai Fai, Alex, and Paul L. Cornelius. "Approximate F-tests of multiple degree of freedom hypotheses in generalized least squares analyses of unbalanced split-plot experiments." Journal of statistical computation and simulation 54.4 (1996): 363-378.
[3]: SAS Institute Inc. 2015. SAS/STAT® 14.1 User’s Guide: The MIXED Procedure. Cary, NC: SAS Institute Inc
[4]: JMP Statistical Discovery LLC 2024. JMP ® 18 Fitting Linear Models. Cary, NC: JMP Statistical Discovery LLC
[5]: Kuznetsova, Alexandra, Per B. Brockhoff, and Rune HB Christensen. "lmerTest package: tests in linear mixed effects models." Journal of statistical software 82 (2017): 1-26.
In reservation-based services with volatile demand and competitive pricing pressures, dynamically optimizing prices is essential for revenue maximization. This paper introduces a data-driven pricing framework that integrates demand forecasting with stochastic optimization. We model customer arrivals using a non-homogeneous Poisson process, where expected demand is estimated through a Poisson Generalized Linear Model (GLM) trained on historical data. Leveraging this demand model, we formulate a dynamic pricing strategy using stochastic dynamic programming to update prices over time, considering real-time availability and market conditions. The approach aims to maximize total expected revenue while adapting to evolving demand patterns.
This paper presents a novel framework for designing adaptive testing procedures by leveraging the properties of waiting-time distributions. The proposed approach integrates temporal information - specifically, the time needed for a specific sequence of correct answers to be realized—into the testing process, enabling a more dynamic and individualized assessment of examinee performance. By modeling waiting times as probabilistic indices of latent ability, cognitive load, or engagement, the framework facilitates real-time adjustment of item difficulty or sequencing. The findings demonstrate that adaptive design leads to substantial reductions in the expected test length while maintaining statistical rigor, offering a practical and efficient tool for modern computerized adaptive testing systems.
Continuous manufacturing (CM) in the pharmaceutical sector integrates the various discrete stages of traditional batch production into a continuous process, significantly decreasing drug product manufacturing time. In CM, where all process units are directly linked, it is crucial to continuously monitor the current process state and maintain consistent product quality throughout manufacturing.
In-process control monitoring is a vital component of the CM control strategy. Given the need to analyze a large volume of data in real time, it is essential to differentiate between genuine process deviations and those caused by machine reading errors. Additionally, given the high volume and frequency of data generated, reevaluating whether an observation is truly an outlier or is a result of measurement error can be both challenging and time-consuming.
To address this challenge, finite mixture models were employed to a case study monitoring various critical quality attributes of tablets, specifically hardness, weight, thickness, and diameter, throughout the entire production process. The evaluation primarily focused on hardness values, with the assumption that both precise and imprecise measurements (resulting from reading errors, e.g. when tablet is not positioned properly in the machine) were present. Various classification thresholds (derived from either the quantile of the correctly-measured group or on the conditional classification curves) were determined based on the model outcomes. Performance of the method was investigated using simulated data based on actual production run.
The landscape of the pharmaceutical industry is evolving. From what was (and still is) a science-centered discipline, more awareness exists nowadays of the opportunities arising from exploring data-driven methodologies to conduct various key activities. In this regard, Chemometrics has been an old-standing ally of the pharmaceutical industry, allowing for real-time assessment of raw materials, online monitoring of processes, and fast batch release. More recently, artificial intelligence and machine learning (AI/ML) have been increasingly applied in R&D, namely in drug/molecular discovery and formulation development, as well as in Process analysis, for instance through retrospective Quality by Design (rQbD) studies. However, there are open problems on the configuration and use of new methodologies, and more research and debate are needed to bring them to the necessary maturity to be deployed and adopted by the highly regulated pharmaceutical sector. This talk is a contribution to this process. Starting from real (and/or realistic) case studies, new methods for active learning are tested and compared against classic methods. Furthermore, the principles for systematically implementing rQbD are presented, and some preliminary results are shared.
Monitoring disease prevalence over time is critical for timely public health response and evidence-based decision-making. In many cases, prevalence estimates are obtained from a sequence of independent studies with varying sample sizes, as commonly encountered in systematic reviews and meta-analyses. Traditional control charts such as the EWMA and CUSUM have been widely used in industrial settings for quality monitoring, but their application to binomial proportions with variable sample sizes remains underexplored.
This work presents an adaptation of the EWMA and CUSUM control charts specifically designed for monitoring proportions (prevalence) in the context of meta-analytic data. The proposed framework dynamically adjusts the control limits based on the sample size of each study, ensuring correct estimation of variability and improving detection power. We derive formulas for control limits under both in-control and out-of-control conditions, and evaluate performance through the Average Run Length (ARL) metrics.
Using both simulated and real-world data on disease prevalence, we demonstrate that the proposed methods can detect both abrupt and gradual changes in prevalence trends. The charts are further shown to be effective tools for identifying outlier studies, shifts due to policy interventions, or emerging epidemiological patterns.
These techniques offer a novel approach for applying industrial statistical methods to public health surveillance and can be extended to other domains where proportions with variable precision are monitored over time.
ENBIS-Live: Real Problems. Real Time. Real Stats.
Join us for one of the most dynamic and interactive sessions of
the ENBIS conference — ENBIS-Live: Open Problem Solving in Action!
This is no ordinary talk. In this fast-paced, high-energy session, statisticians and
data scientists roll up their sleeves to tackle real-world open problems — live and
on the spot. Think of it as a collaborative brain trust powered by the collective
wisdom and creativity of the ENBIS community.
Here’s how it works:
🔍 Got a tricky problem? Volunteer to present it in 7 minutes. Outline the
background, the data science or statistical angle, and where you're stuck.
❓ Need clarity? The audience asks their burning questions.
💡 Have ideas? The floor opens to contributions, suggestions, and insights from
the crowd.
🧠 Wrap-up: The problem owner reflects on the input, and the session host ties it
all together.
Each problem gets 20–30 minutes of focused, expert attention. We’ll feature 2–3
open problems — so come ready to think, question, suggest, and be inspired!
Got a challenge you'd like to throw into the ring? Contact Jennifer Van Mullekom
(vanmuljh@vt.edu) and be part of this one-of-a-kind problem-solving spectacle.
Bring your brains. Bring your curiosity. And let’s solve some problems — ENBIS-
style.
On nuclear sites, such as nuclear power plants, instruments for measuring atmospheric radioactivity are deployed to ensure the radiation protection of workers. This type of instrument continuously samples ambient air aerosols on a filter, measures as an energy spectrum the radioactivity accumulated on the filter in real time, and shall notify the operator if transuranic alpha emitters are detected. In the specific case of nuclear facilities dismantling, sudden variations in aerosol ambiance, both in terms of size distribution and concentration, lead to a deterioration of the nuclear measurement, and often to a false alarm.
In this work, we first developped a nuclear code to generate semi-synthetic training data. We then constructed a deep learning algorithm that accurately detect the presence, or absence, of artificial alpha emitters based on the knowledge of the raw nuclear measurement, even in atypical atmospheric conditions.
The “black-box” aspect of decision-making of neural networks in an issue as sensitive as nuclear safety represents a major obstacle to the use of these techniques in practice. Therefore, we first implement a tool to visualize the classification process of the model (explainability). Moreover, theoretical guaranties can be imposed on the model for better interpretability, even though it can lead to the deterioration of pure performances. In particular, a partially isotonic neural network is developed to integrate prior physical knowledge on the problem. Forecasts are also calibrated to match an interpretable probability. Lastly, an uncertainty analysis of the model output is performed taking into account the different sources of uncertainties.
Additive functional decomposition of arbitrary functions of random elements, under the form of high-dimensional model representations is crucial for global sensitivity analysis and more generally understanding black-box models. Formally, for random inputs $X = (X_1, \dots, X_d)^\top$, and an output $G(X)$, it amounts to finding the unique decomposition
\begin{equation}
G(X) = \sum_{A \in D} G_A(X_A) \quad \quad \quad(1)
\end{equation}
where $D = \{1, \dots, d\}$, $D$ is the set of subsets of $D$, and $G_A(X_A)$ are functions of the subset of input $X_A = (X_i)_{i \in A}$. Whenever the $X_i$ are assumed to be mutually independent, such a decomposition is known as Hoeffding's decomposition. It is well known to allow the derivation of meaningful Sobol' indices for the analysis of the output variance, among others. Whenever the inputs are not assumed to be mutually independent, several generalizing approaches have been proposed in the literature, but at the price of imposing restrictive assumptions on the correlation structure or lacking interpretability.
By viewing random variables as measurable functions, we prove that a unique decomposition such as (1), for square-integrable black-box outputs $G(X)$, is indeed possible under fairly reasonable assumptions on the inputs:
Novel sensitivity indices based on this generalized decomposition can be proposed, along with theoretical arguments to justify their relevance. They can disentangle effects due to interactions and due to the dependence structure. Such indices will be discussed, in light of recent results obtained for numerical models with multivariate Bernoulli inputs, used in numerous applications.
This presentation explores the application of innovative deep learning architectures to enhance electricity demand forecasting in decentralised grid systems, with a focus on the French energy market. Generalised Additive Models (GAMs), which are state of the art methods for electricity load forecasting, struggle with spatial dependencies and high-dimensional interactions inherent in modern grids. To address these gaps, we propose complementary deep learning frameworks: Graph Neural Networks (GNNs) for modeling spatial hierarchies across regions, multi-resolution Convolutional Neural Networks (CNNs) for integrating heterogeneous temporal data, and meta-learning techniques like the DRAGON framework to optimize neural architectures automatically. A case study forecasts 2022 French national electricity load at three hierarchical levels—national, regional (12 regions), and city (12 cities)—using a composite loss function (RMSE) and open datasets from RTE and Météo France. Despite their expressive power and strong performance, interpreting these models remains a challenge and a priority for electricity market stakeholders. While it is not the central focus of this work, we will outline some perspectives and general ideas that may contribute to a better understanding of these models.
We propose a novel federated learning framework on a network of clients with heterogeneous data. Unlike conventional federated learning, which creates a single aggregated model shared across all nodes, our approach develops a personalized aggregated model for each node using the information (and not the raw data) of neighboring nodes in the network. To do so, we leverage the topology of the underlying (similarity) network to guide how models (nodes) influence one another. While our approach is general to any modeling framework, we create a formulation based on Generalized Linear Models (GLMs). To estimate the model parameters, we develop a decentralized optimization algorithm based on the alternating direction method of multipliers (ADMM) to efficiently solve the problem without central coordination. Experimental results demonstrate that our method outperforms existing federated and personalized learning baselines in terms of predictive performance, adaptability, and robustness to network sparsity.
In the realm of machine learning, effective modeling of heterogeneous subpopulations presents a significant challenge due to variations in individual characteristics and behaviors. This paper proposes a novel approach for addressing this issue through Multi-Task Learning (MTL) and low-rank decomposition techniques. Our MTL approach aims to enhance personalized modeling by leveraging shared structures among similar tasks while accounting for distinct subpopulation-specific variations. We introduce a framework where low-rank decomposition is used to decompose the task model parameters into a low-rank structure that captures commonalities and variations across tasks and subpopulations. This approach allows for efficient learning of personalized models by sharing knowledge between similar tasks while preserving the unique characteristics of each subpopulation. Experimental results on simulation and two case studies from healthcare domain demonstrate the superior performance of the proposed method compared to several benchmarks. The proposed framework not only improves prediction accuracy but also enhances interpretability by revealing underlying patterns that contribute to the personalization of models.
Diffusion models have proven effective for generative modeling, denoising, and anomaly detection due to their ability to capture complex, high-dimensional, and non-linear data distributions. However, they typically require large amounts of non-anomalous training data, limiting their use when data is unlabeled and contains a mix of contaminated and uncontaminated samples. We propose a novel Robust Diffusion model that integrates robust statistical techniques to train diffusion models without relying on purely clean data. This approach enhances resilience to data contamination while preserving the model’s learning capacity. Extensive simulations and a real-world case study show that our method consistently outperforms existing diffusion-based and statistical approaches across multiple anomaly detection metrics.
Monitoring the occurrence of undesirable events, such as equipment failures, quality issues or extreme natural phenomena, requires tracking both the time between events (T) and their magnitude (X). Time Between Events and Amplitude (TBEA) control charts have been developed to monitor these two aspects simultaneously. Traditional approaches assume known distributions for T and X. However, in practice, identifying the true distribution of these variables is challenging. To address this difficulty, distribution-free TBEA control charts have been proposed. Furthermore, in addition to signaling an alarm (i.e. identifying the detection time), it is often beneficial to estimate the instant at which the change occurred (i.e. the change-point time). Knowing when a shift occurred in a TBEA statistic can help trace potential causes and improve overall process understanding. This study proposes non-parametric change-point control charts for monitoring TBEA data. Through a simulation experiment and a case study, the statistical properties of the change point control charts are evaluated and compared with those of a control chart specifically designed for monitoring time between events and amplitude data. The results suggest that change-point control charts can be effectively used within the time between events and amplitude framework, providing valuable support in process management.
We study the problem of transforming a multi-way contingency table into an equivalent table with uniform margins and same dependence structure. This is an old question which relates to recent advances in copula modeling for discrete random vectors. In this work, we focus on multi-way binary tables and develop novel theory to show how the zero patterns affect the existence of the transformation as well as its statistical interpretability in terms of dependence structure. The implementation of the theory relies on combinatorial and linear programming techniques, which can also be applied to arbitrary multi-way tables. In addition, we investigate which odds ratios characterize the unique solution in relation to specific zero patterns. Several examples are described to illustrate the approach and point to interesting future research directions.
The talk is based on a recent joint work with Elisa Perrone (Eindhoven University of Technology, Eindhoven, The Netherlands) and Fabio Rapallo (Università di Genova, Genova, Italy).
We consider a framework which addresses the search for an optimal maintenance policy of a system by using observed system state data to learn the degradation model on one hand, and by using simulation from the learned model to obtain future states and rewards to update the value function and improve the current policy, on the other hand. We apply this framework to the maintenance of lithium-ion batteries.
This work is part of the PRIN 2022 project no. 2022WBN75S - E3DM - Experimental Design and Maintenance, a Decision-Making approach driven by Degradation Models
Classification is the activity of assigning objects to some pre-existing exclusive categories that form a comprehensive spectrum (scale) of the studied property. The classifier can be a person, a machine, an algorithm, etc. Classification accuracy is a combination of trueness and precision. The latter (precision), perceived as the 'closeness of agreement' between results of multiple classifications of identical items under stipulated conditions, is split into two components. The intra-component (repeatability) characterizes the dispersion of results from the same classifier. The inter-component characterizes the dispersion of results due to the participation of different classifiers in the classification process (e.g., in collaboration studies).
Identity is the key concept that distinguishes the metrological perception of "closeness of agreement" from the one accepted in the field of social sciences (such as Fleiss' kappa measure, for example). Identity is necessary to isolate that part of the non-reproducibility that is associated only with the measurement procedure. Two distinctive features of the proposed measure of expected agreement between independent classifiers are:
- It obeys the superposition principle, i.e. the total measure equals the weighted sum of partial measures, where the ‘‘weight’’ of every category is the probability of an item in the test to belong to this category.
- For any number of classifiers, it is expressed through repeatability and reproducibility variations only.
We intend to demonstrate the proposed measure using various practical examples.
Nuclear fusion holds the promise of clean, virtually limitless energy. For fusion reactions to occur in the plasma, extreme temperatures must be reached – up to 150 million degrees Celsius. This constitutes an immense engineering challenge, requiring a necessary degree of accuracy. The Neutral Beam Injection (NBI) is one key technology enabling the auxiliary heating of the plasma. Fast neutral particles bypass the strong magnetic field confining the plasma, ionizing and subsequently transferring their energy through plasma collisions. The NBI heating heavily depends on the plasma state, which is difficult to measure directly, and also on ionization data, which stems from quantum mechanics. Furthermore, the scenario where most of the beam does not ionize and deposits its energy on the wall of the device, thus damaging it, must be avoided.
We employ Uncertainty Quantification (UQ) and Sensitivity Analysis (SA) methods, in order to inform investment decisions in such high-stakes fusion energy projects, aiming at reducing risk. We consider parametric uncertainty for the modeling of the NBI heating through the TAPAS code. Through Latin Hypercube Sampling (LHS), the multi-dimensional input space of the uncertainty sources is efficiently explored. Through uncertainty propagation into the TAPAS code, multiple surrogate models are constructed, including Polynomial Chaos Expansion (PCE) and Gaussian Processes (GP), which allow for accurate uncertainty intervals. The surrogates enable rapid scenario analysis, leading to a Sensitivity Analysis (SA) through the computation of the Sobol’ indices, which reveal the most influential factors driving the variability of the code output.
This study explores the use of the Network Density Index and the Extreme Downside Correlation(EDC) matrix to detect systemic stress periods and identify inter-country vulnerability clusters in the European electricity market. The analysis reveals a critical stress phase in mid-2022 and shows how extreme event interconnections reflect infrastructure constraints and regional dependencies. These findings suggest practical applications for early warning systems, stress testing, and cross-border risk management strategies, with implications for regulators and transmission system operators.
São Paulo, one of the largest cities in the world, is implementing one of the most extensive primary healthcare accreditation projects ever conducted, covering 465 Basic Health Units (UBS) and reaching approximately seven million users of Brazil’s Unified Health System (SUS). This initiative is part of the municipal program called “Avança Saúde” and follows the methodology of the National Accreditation Organization (ONA, from the Portuguese Organização Nacional de Acreditação), Brazil’s leading healthcare accreditation framework.
This study presents an approach that integrates applied statistics and artificial intelligence to develop a predictive model based on historical data from assessment cycles (organizational diagnosis, self-assessment, and certification). The modeling process was conducted employing computational tools and programming techniques in Python and R, to execute data engineering tasks—including extraction, cleaning, transformation, and integration—and to perform rigorous analyses of large-scale operational and administrative datasets.
The predictive model is intended to support public health decision-making by enabling the prioritization of health units with the greatest potential for improvement within the accreditation process, thereby optimizing resource allocation. All data were sourced from the ONA Integrare system, in compliance with ethical standards and data anonymization protocols.
With over 50,000 Basic Health Units operating throughout Brazil, this research demonstrates high potential for large scale implementation in Brazil, offering evidence-based strategies to enhance primary care quality and strengthen the SUS across diverse contexts.
Missed appointments in diagnostic services contribute significantly to healthcare inefficiencies, increased operational costs, and delayed patient care. This study explores the use of data-driven predictive models to identify patients at high risk of no-show behavior in diagnostic scheduling. The analysis focuses on the MRI department, where the impacts of no-shows are particularly crucial. By leveraging historical appointment data, demographic information, and behavioral patterns, machine learning algorithms were trained and validated to forecast no-show likelihood. The proposed model demonstrates strong predictive performance and offers actionable insights for healthcare administrators to implement targeted interventions such as reminder systems or overbooking strategies.
The paper examines the factors that may signal the existence of potential fraud in companies’ financial statements. Using a sample of the Russell 3000 firms from 2000 to 2023, we explore the relationship between various accounting, audit, internal control and market variables and the presence of fraud indicators. Two dependent variables are employed as proxies for potential fraud: the existence of Key Audit Matters (KAMs) reported by auditors and the restatement of financial statements.
The independent variables examined include audit - non-audit fees ratio, changes in company’s market value, going concern issues, auditor tenure, control risk, profitability, loan leverage, and auditor size. The objective is to assess whether these factors can statistically predict the presence of fraud-related red flags in financial reporting. Our research contributes to the literature on audit quality, corporate governance, and financial reporting reliability by offering insights into the potential predictors of fraud indications in audited financial statements.
Calibrating a simulation model involves estimating model's parameters by comparing its outputs with experiences to ensure that simulation results accurately reflect those experiences. However, when outputs are functions of time, there are multiple ways to define the difference between experimental and simulated outputs. It has recently been proposed to use elastic functional data analysis, which makes it possible to decompose a functional output into two new functions: a temporally aligned function and its corresponding warping function. This approach splits the problem into two independent calibration tasks to address functional misalignment. The first task is based on the comparison of the aligned functions and the second one is based on the comparison of the warping functions. In this work, we develop this framework with the use of Gaussian process regression, we apply it to the calibration of the Johnson damage model, which describes spallation in ductile materials, and we compare it to a Bayesian calibration method that does not use functional alignment.
Innovation diffusion phenomena have long attracted researchers due to their interdisciplinary nature, which allows for integrating theories and concepts from various fields, including natural sciences, mathematics, physics, statistics, social sciences, marketing, economics, and technological forecasting. The formal representation of diffusion processes has historically relied on epidemic models borrowed from biology—namely, the logistic or S-shaped equation—based on the hypothesis that innovations spread within a social system through interpersonal communication, much like diseases spread through contagion.
Today, we are witnessing numerous diffusion processes of diverse nature, significantly accelerated by unprecedented mobility patterns and communication capabilities. These range from the spread of new epidemics to the widespread adoption of technologies and products, from the rapid dissemination of news to the broad acceptance of the latest trends and technologies. As some of these processes demonstrate, large-scale, rapid diffusion requires significant efforts to control its impact on socio-economic systems and the environment and to inform effective policy decisions.
Therefore, it is especially important to illuminate these processes through timely investigation and prediction of their evolution, both in terms of speed and scale. Gaining a better understanding of their underlying—sometimes hidden—dynamics requires combining techniques and methodologies. These theories and methods stand to benefit significantly from new and current applications, supported by recent advancements in data collection technologies.
This paper discusses theoretical and methodological aspects of innovation diffusion models and recent developments in model building and statistical inference. These could provide valuable insights into various domains, including new product forecasting, marketing, consumer behavior, and the social sciences.
In recent decades, numerical experimentation has established itself as a valuable and cost-effective alternative to traditional field trials for investigating physical phenomena and evaluating the environmental impact of human activities. Nevertheless, high-fidelity simulations often remain computationally prohibitive due to the detailed modelling required and the complexity of parameter selection. To overcome these challenges, surrogate models constructed from a limited number of complex model evaluations are commonly used to drastically reduce computational costs and quantify uncertainties. In this context, we propose an active learning approach that, for a fixed evaluation budget, intelligently reduce the dimension of the input space to optimize surrogate model performance.
Specifically, our methodology builds on new advances in active learning for sensitivity analysis—such as Sobol indices and Derivative-based Global Sensitivity Measures (DGSM)—by leveraging derivatives obtained from a Gaussian Process (GP) surrogate. The benefits of our approach are demonstrated through several case studies, ranging from synthetic benchmark functions to a real-world environmental application involving physically-based modelling of pesticide transfer. Our results highlight the potential of this strategy to enhance sensitivity analysis in computationally intensive modelling scenarios.
In pharmaceutical statistics, traditional outlier detection often focuses on univariate methods. However, a multivariate approach is essential for analysing complex datasets representing critical quality attributes, such as assay, dissolution, and disintegration time.
The Shiny-for-Python application described here employs advanced machine learning techniques, specifically Principal Components Analysis (PCA) and k-Nearest Neighbours (k-NN), to classify outliers in multivariate datasets relevant to the pharmaceutical industry. PCA facilitates dimensionality reduction, enhancing the visualization of data structures and identifying abnormal patterns. To strengthen our outlier detection approach, the medcouple statistic is integrated to determine an upper limit in the distribution of k-NN distances. This enables a detection mechanism tailored for skewed data.
The application brings accessibility to the methodology, making it easier for practitioners to implement advanced statistical techniques in their work. In many cases, scientists encountering outliers need to act immediately as conditions can change rapidly. Real-time analysis is critical, as immediate insights support informed decision-making and improve operational efficiency.
While traditional methods like Univariate Statistical Process Control (USP) may struggle with multivariate data, the combination of PCA, k-NN, and the medcouple enhances outlier detection. Additionally, the ongoing challenge of integrating real-time outlier detection with data analytics in pharmaceutical processes promotes better risk management and compliance.
An important parameter in pharmacological research is the half-maximal inhibitory concentration (IC50/EC50), which quantifies the potency of a drug by measuring the concentration required to inhibit a biological process by 50%. The 4-parameter logistic (4PL) model is widely employed for estimating IC50/EC50 values, as it provides a flexible sigmoidal fit. Meta-analysis on the other hand, has become an indispensable tool for synthesizing the results of independent studies into a unified, statistically robust estimate and facilitates the decision making in various fields from medicine to economics. In this work, we discuss methods for meta-analysis of IC50/EC50 values arising from independent studies. We first show the application of standard summary data methods that pool IC50/EC50 estimates obtained from independent studies, and then we proceed with more advanced methods that allow the calculation of an entire pooled sigmoid curve, using multiple measurements per study and estimating all parameters of interest in a single step. We discuss non-linear estimation methods in Stata using the nl and menl commands for fixed and random effects, respectively. We also show that in some special cases, when the upper and lower asymptote of the sigmoid curve is 1 and 0, respectively, the model reduces to a two-parameter logistic (2PL) model. In this framework, variants of the generalized linear model, such as the fractional logistic regression model, fitted with specialized commands such as glm, fracreg, or gllamm, can be used to obtain the pooled sigmoid curve with all parameters of interest, either under fixed or random effects. We present examples of the methods and discuss details of the implementation.
In a world saturated with data and methodological research, the ability to communicate statistical insights clearly and compellingly is as critical as the models we build and the methods we develop. This talk explores the art and science of data storytelling through the three rhetorical lenses of Logos (logic and reason), Ethos (credibility and character), and Pathos (emotion and connection) as first articulated by Aristotle in his treatise Rhetoric. For practicing statisticians and data scientists, mastering these elements transforms technical findings into narratives that influence decisions, inform policy, and inspire change. For methodological researchers, ethos, pathos, and logos can enhance research storytelling as well. With transparent, clear and concise communication rooted in neuroscience, practitioners are more likely to recall and select state of the art methods presented by researchers. In this way, researchers influence data centric decisions, inform analysis-driven policy, and inspire effective change.
Each rhetorical pillar will be defined in the context of scientific, data-based communication. Together, we will explore how our discipline engrains thought patterns that work against effective use of the three pillars. Attendees will be introduced to story structures and frameworks that simplify the communication of real-world, data-centric work. The talk will include practical tips and tricks such as how to explain uncertainty in an understandable way, how to tailor a narrative to diverse audiences, and how to avoid common storytelling pitfalls like misaligned visuals or cognitive overload. Each tip or framework will be accompanied by examples, resulting in future statistics and data science stories that are not only technically sound but also rhetorically powerful.
https://conferences.enbis.org/event/81/
https://conferences.enbis.org/event/80/